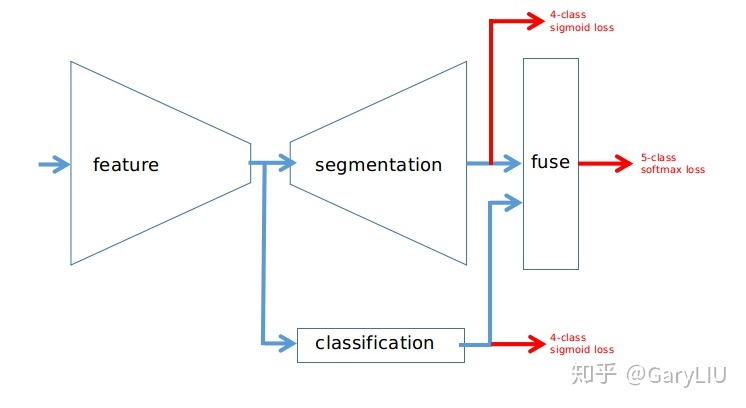
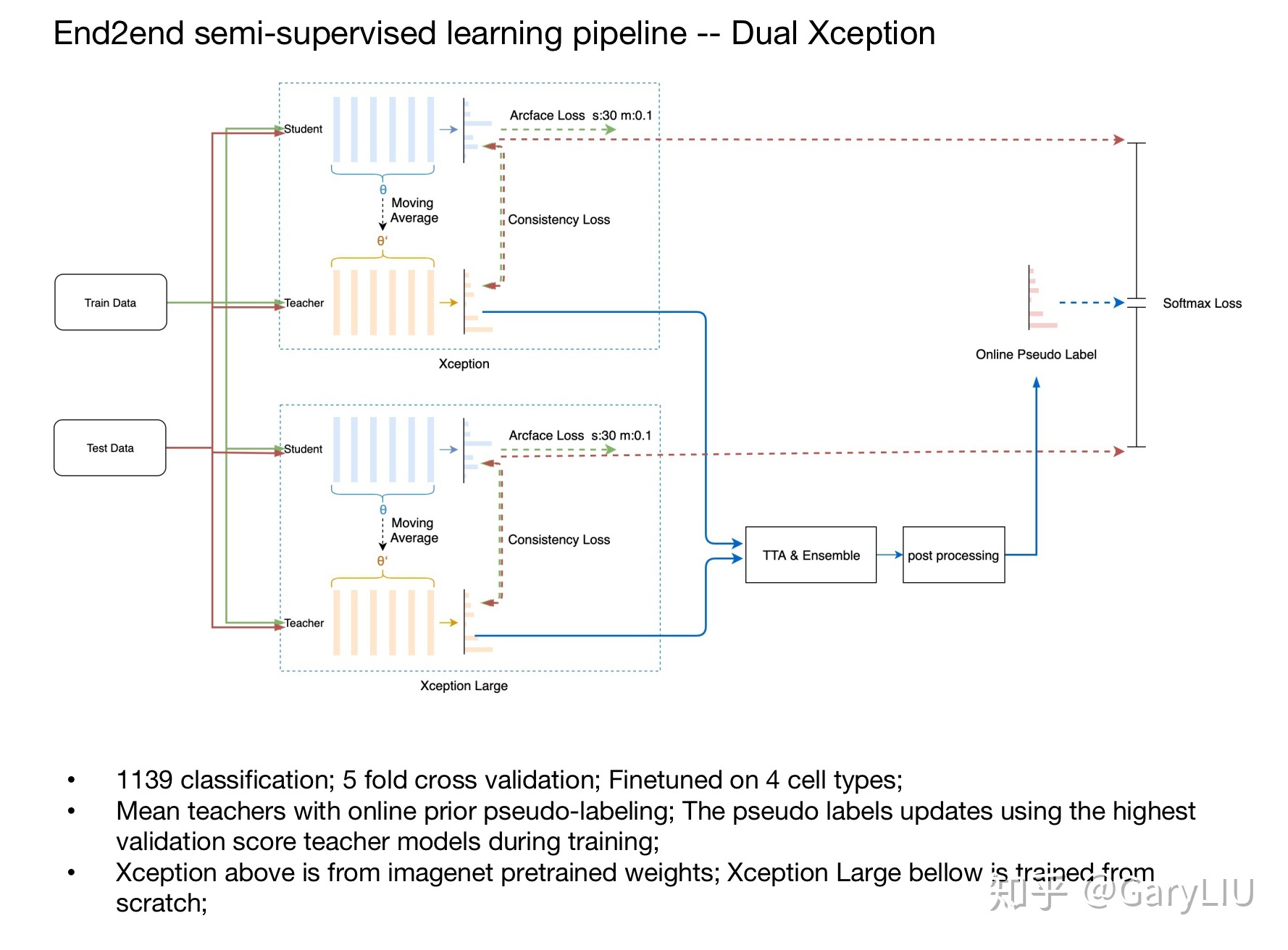
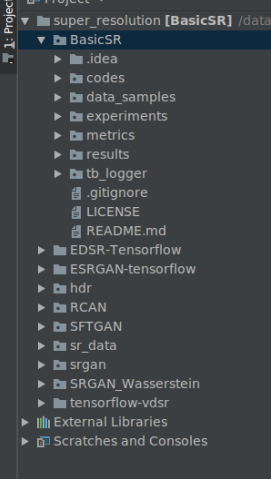
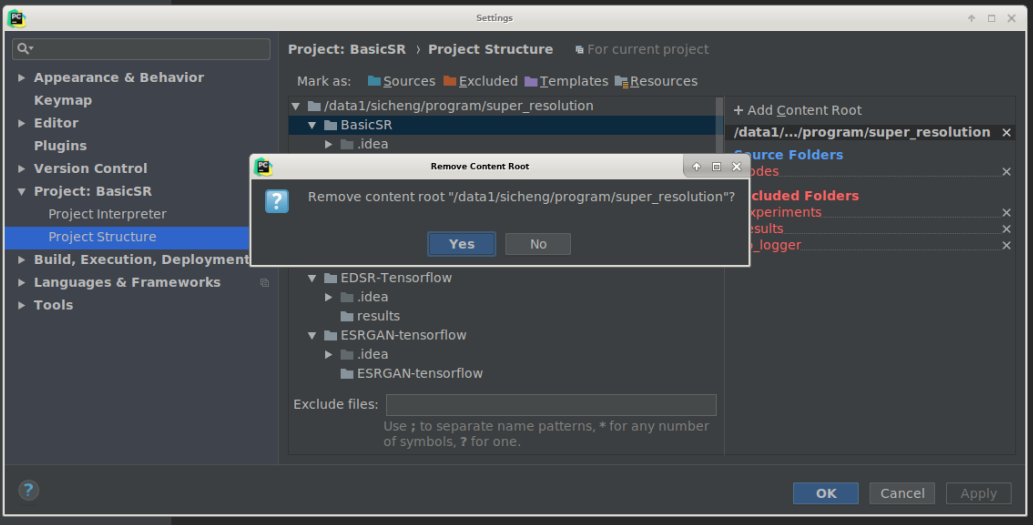
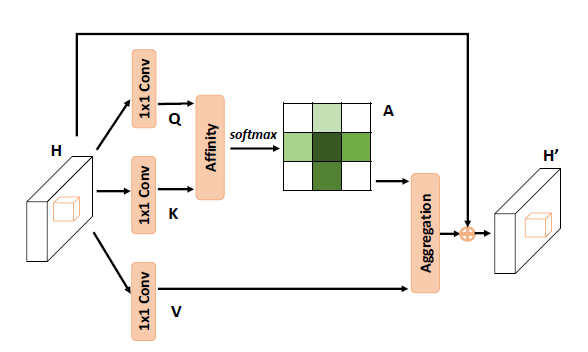
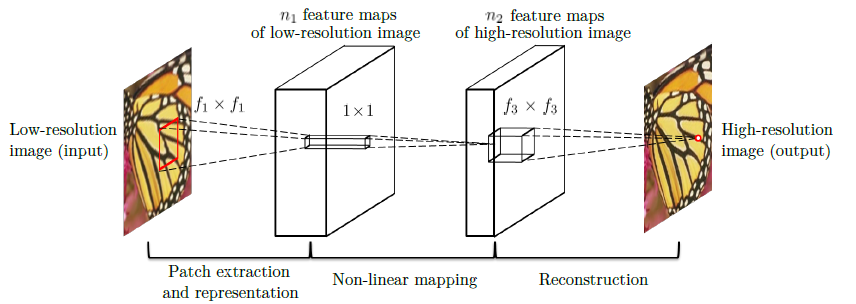
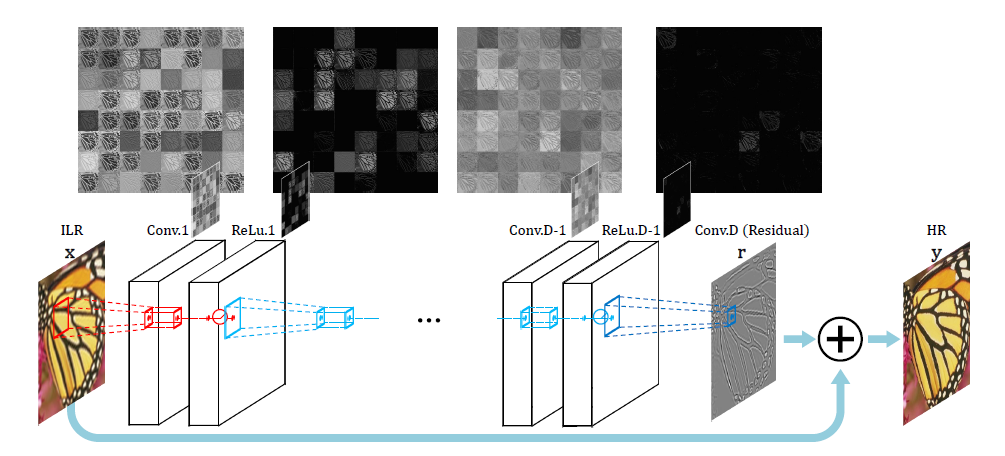
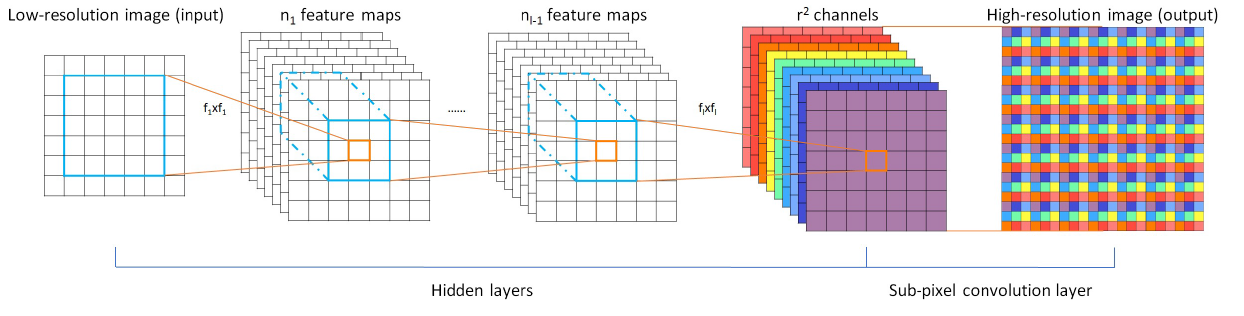
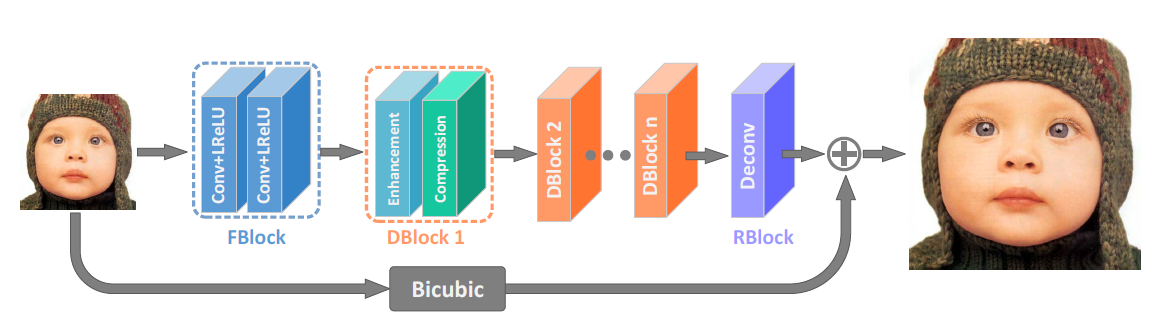
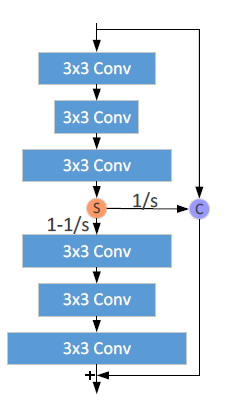
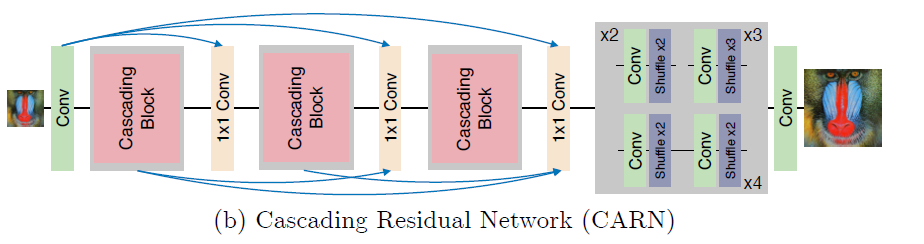
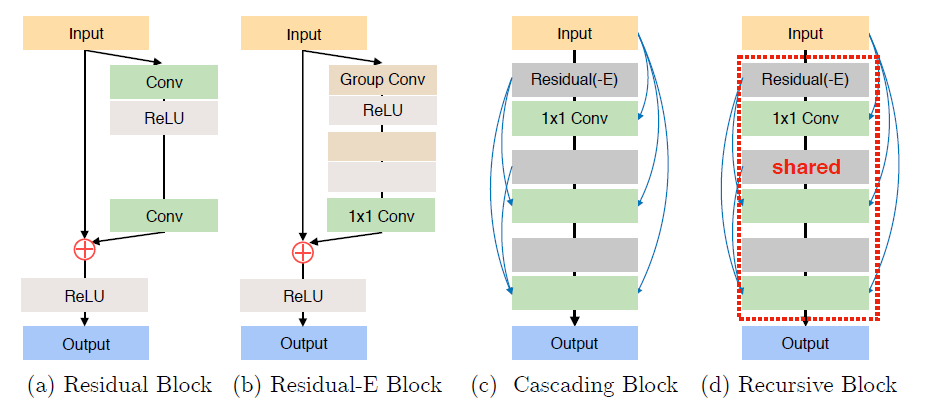
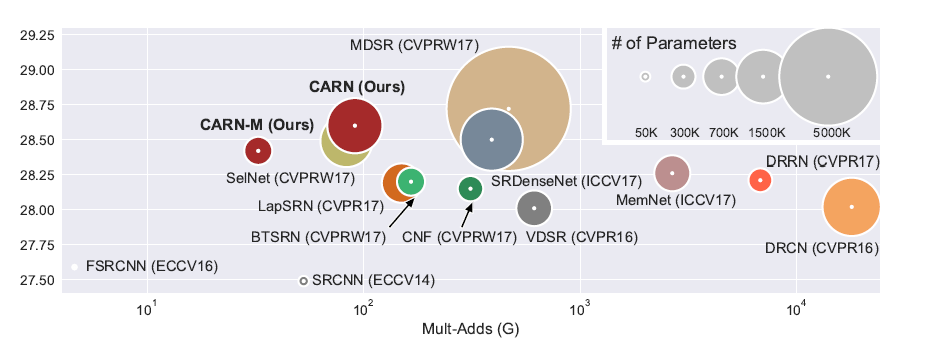
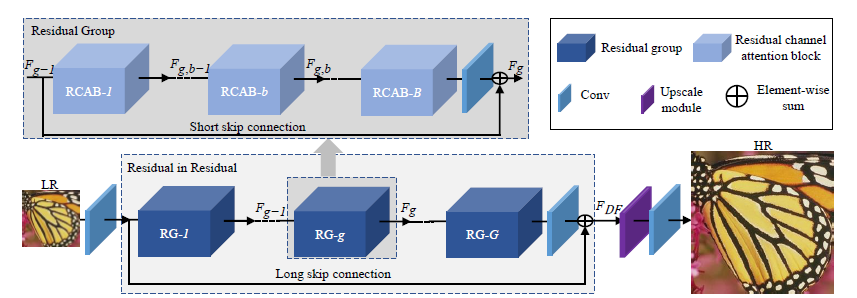
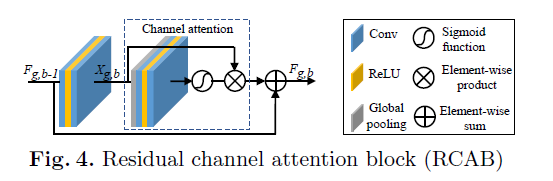
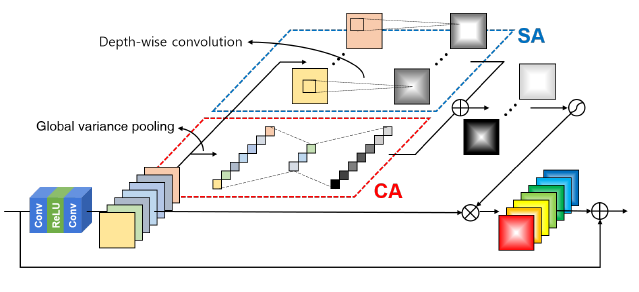
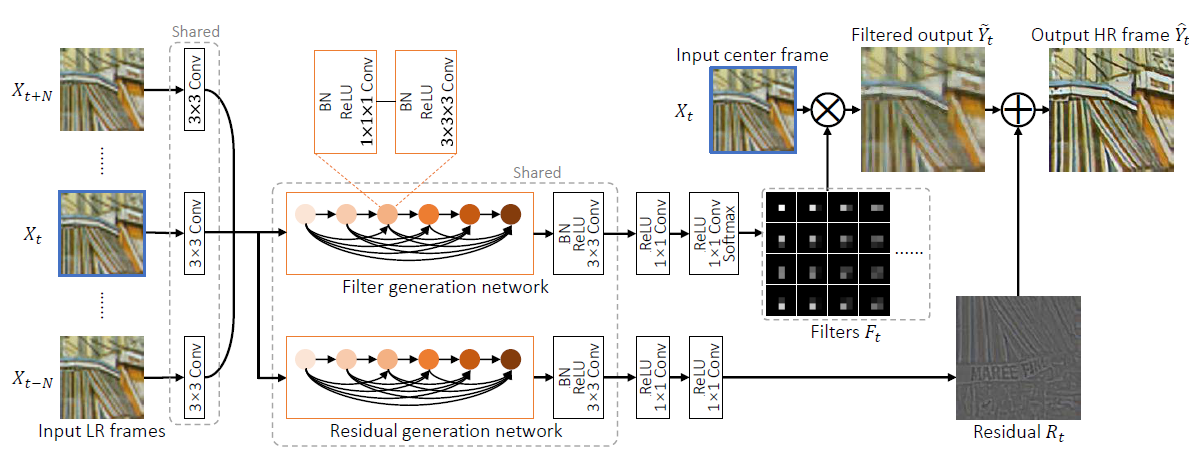
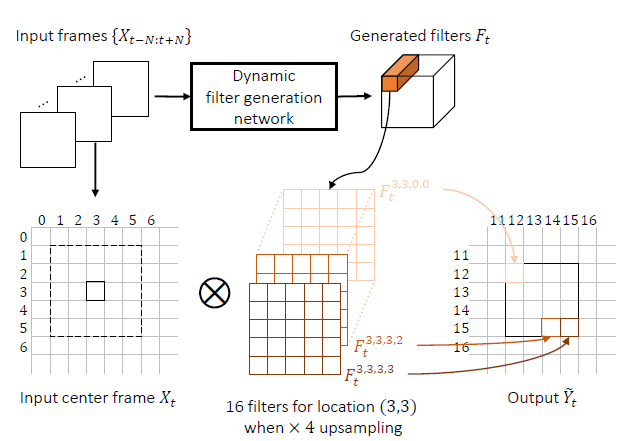
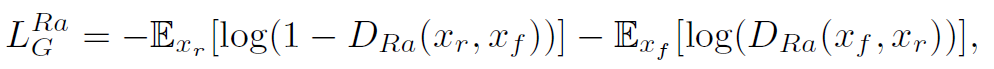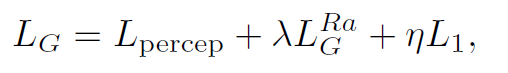2. Add Two Numbers
题目描述
给出两个 非空 的链表( linked lists)用来表示两个非负的整数。其中,它们各自的位数是按照 逆序 的方式存储的,并且它们的每个节点只能存储 一位 数字。
如果,我们将这两个数相加起来,则会返回一个新的链表来表示它们的和。
您可以假设除了数字 0 之外,这两个数都不会以 0 开头。
示例
1 | 输入:(2 -> 4 -> 3) + (5 -> 6 -> 4) |
Solution
1 | # Definition for singly-linked list. |
注意
1.Python2用/ Python3用 // 表示下取整的除法
2.链表的构建1
2
3
4
5
6head = curr = ListNode(0)
...
curr.next = ListNode(XX)
curr = curr.next
...
return head.next
3.生成链表的方法及本题测试代码
1 | def generateList(l: list) -> ListNode: |
3. Longest Substring Without Repeating Characters
题目描述
给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。。
示例
1 | 输入: "abcabcbb" |
Solution1
1 | class Solution: |
Solution2
1 | class Solution: |
5. Longest Palindromic(回文) Substring !!!!!!!!!!!!!!!!
题目描述
给定一个字符串 s,找到 s 中最长的回文子串。你可以假设 s 的最大长度为 1000。
示例
1 | 输入: "babad" |
Solution
6. ZigZag Conversion (Z字形变换)
相关标签: 字符串
题目描述
将一个给定字符串根据给定的行数,以从上往下、从左到右进行 Z 字形排列。
比如输入字符串为 “LEETCODEISHIRING” 行数为 3 时,排列如下:1
2
3L C I R
E T O E S I I G
E D H N
之后,你的输出需要从左往右逐行读取,产生出一个新的字符串,比如:”LCIRETOESIIGEDHN”。
请你实现这个将字符串进行指定行数变换的函数 string convert(string s, int numRows);
示例
1 | 输入: s = "LEETCODEISHIRING", numRows = 3 |
Solution
1 | class Solution: |
11. Container With Most Water
相关标签: 双指针
题目描述
给定 n 个非负整数 a1,a2,…,an,每个数代表坐标中的一个点 (i, ai) 。在坐标内画 n 条垂直线,垂直线 i 的两个端点分别为 (i, ai) 和 (i, 0)。找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水
示例
1 | 输入: [1,8,6,2,5,4,8,3,7] |
Solution
1 | class Solution: |
思路
算法流程: 设置双指针 i,j 分别位于容器壁两端,根据规则移动指针(后续说明),并且更新面积最大值 res,直到 i == j 时返回 res。
指针移动规则与证明: 每次选定围成水槽两板高度 h[i],h[j]中的短板,向中间收窄 111 格。以下证明:
- 设每一状态下水槽面积为 S(i,j),(0<=i<j<n),由于水槽的实际高度由两板中的短板决定,则可得面积公式 S(i,j)=min(h[i],h[j])×(j−i)S(i, j)。
- 在每一个状态下,无论长板或短板收窄 1格,都会导致水槽 底边宽度 −1。
- 若向内移动短板,水槽的短板 min(h[i],h[j])可能变大,因此水槽面积 S(i,j)S(i, j)S(i,j) 可能增大。
- 若向内移动长板,水槽的短板 min(h[i],h[j])不变或变小,下个水槽的面积一定小于当前水槽面积。
12. Integer to Roman
相关标签: 字符串
题目描述
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。1
2
3
4
5
6
7
8字符 数值
I 1
V 5
X 10
L 50
C 100
D 500
M 1000
例如, 罗马数字 2 写做 II ,即为两个并列的 I。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。
通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况:
I 可以放在 V (5) 和 X (10) 的左边,来表示 4 和 9。
X 可以放在 L (50) 和 C (100) 的左边,来表示 40 和 90。
C 可以放在 D (500) 和 M (1000) 的左边,来表示 400 和 900。
给定一个整数,将其转为罗马数字。输入确保在 1 到 3999 的范围内。
示例
1 | 输入: 3 |
Solution
1 | class Solution: |
15. 3SUM
相关标签: 双指针 数组
题目描述
给定一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?找出所有满足条件且不重复的三元组。
注意:答案中不可以包含重复的三元组。
示例
1 | 给定数组 nums = [-1, 0, 1, 2, -1, -4], |
Solution
1 | class Solution: |
思路

16. 3Sum Closest
相关标签: 双指针 数组
题目描述
给定一个包括 n 个整数的数组 nums 和 一个目标值 target。找出 nums 中的三个整数,使得它们的和与 target 最接近。返回这三个数的和。假定每组输入只存在唯一答案。
示例
1 | 给定数组 nums = [-1,2,1,-4], 和 target = 1. |
Solution
1 | class Solution: |