Basic Detection Framework
Two stage:
[R-CNN]
[SPP-Net]
[Fast R-CNN]
[Faster R-CNN]
One stage:
[YOLO]
[SSD]
[YOLOv2]
[YOLOv3]
Improvement for Two Stage Framework
To alleviate the problems arising from scale variation and small object instances
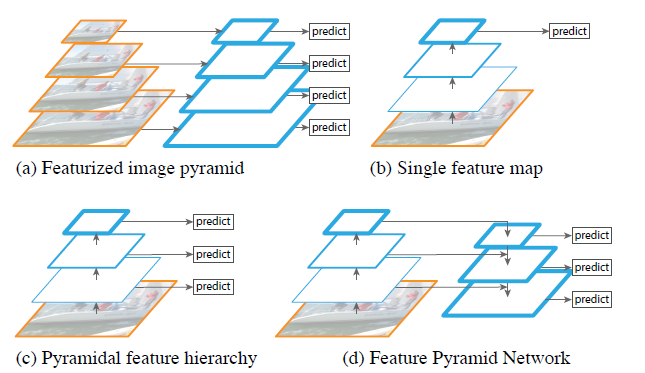
Construct feature pyramid
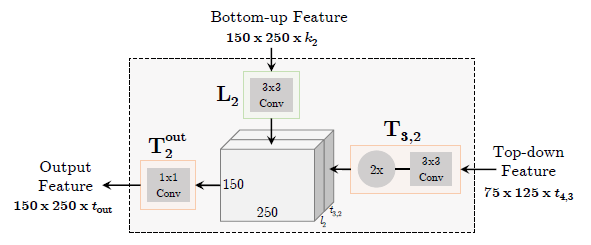
[FPN - CVPR2017] Feature Pyramid Networks for Object Detection
[paper] https://arxiv.org/abs/1612.03144
[summarization]
-Difference with previous segmentation methods which use top-down and skip connections architecture: predictions are independently made on each level.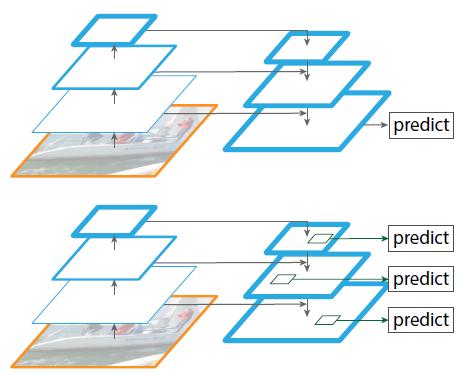
-The topdown pathway hallucinates higher resolution features by upsampling spatially coarser, but semantically stronger, feature maps from higher pyramid levels.
-Each lateral connection merges feature maps of the same spatial size from the bottom-up pathway and the top-down pathway.
-The bottom-up feature map is of lower-level semantics, but its activations are more accurately localized as it was subsampled fewer times.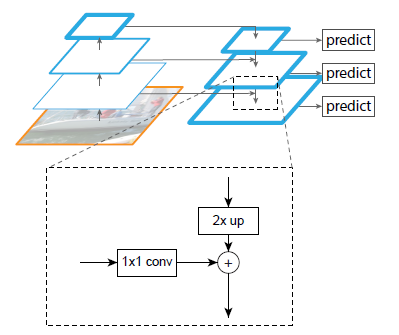
[TDM - CVPR2017] Beyond Skip Connections: Top-Down Modulation for Object Detection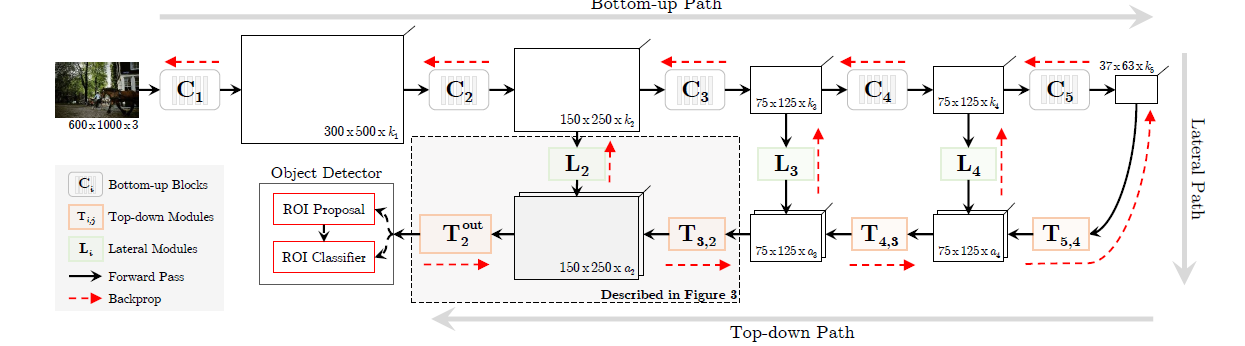
Multi-scale training approach (image pyramid)
[SNIP - CVPR2018] An Analysis of Scale Invariance in Object Detection – SNIP
[paper] https://arxiv.org/abs/1711.08189
[summarization]
-Scale Normalization for Image Pyramids
-Use Image Pyramids, for each image(with multi-scale), training is only performed on objects that fall in the desired scale range and the remainder are simply ignored during back-propagation
-Deformable R-FCN + Soft-NMS ResNet-101/DPN-98 -> 48.3mAP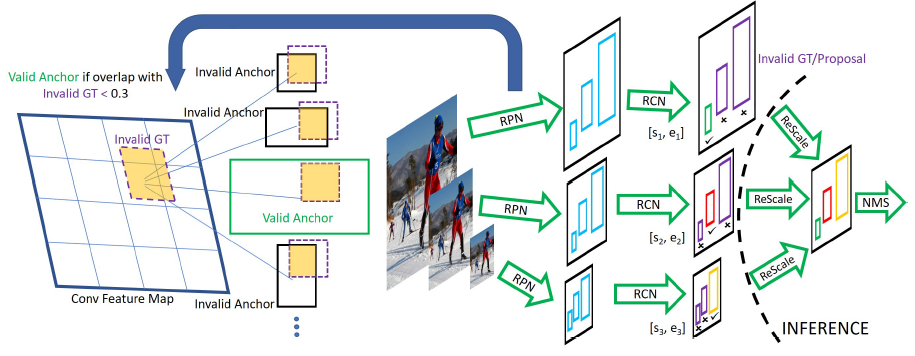
[SNIPER - NIPS2018] SNIPER: Efficient Multi-Scale Training
[paper] https://arxiv.org/abs/1805.09300
[official code] https://github.com/mahyarnajibi/SNIPER
[summarization]
-Chip Generation: For each scale, KxK pixels chips are placed at equal intervals of d pixels
-Positive Chip Selection: A ground-truth box is said to be covered if it is completely enclosed inside a chip. Ground-truth instances which have a partial overlap (IoU > 0) with a chip are cropped. All the cropped ground-truth boxes (valid or invalid) are retained in the chip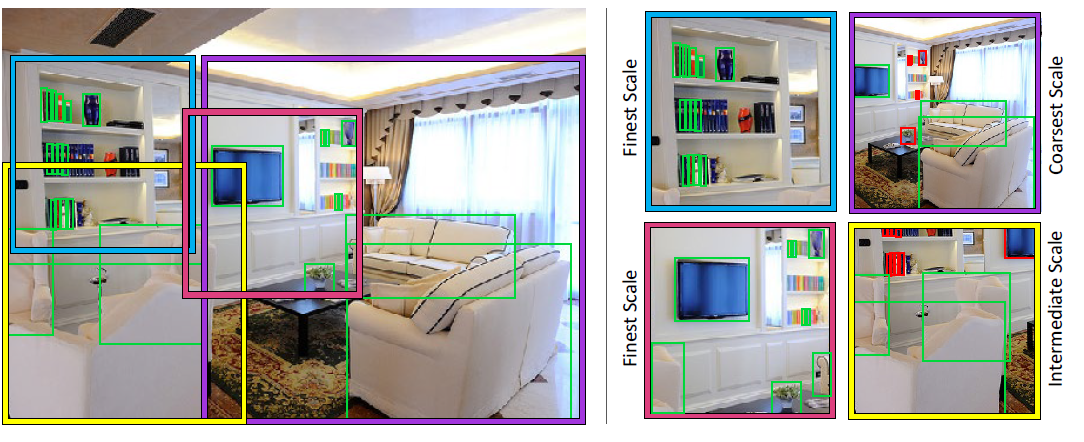
-Negative Chip Selection:First train RPN for a couple of epochs. Then, for each scale i, we greedily select all the chips which cover at least M proposals.
To improve localization accuracy
Improve bounding box refinement method
Previous method: Using iterative bounding box regression to refine a bounding box.
This idea ignores two problems:
(1) a regressor trained at low IoU threshhold (such as 0.5, used to defind postives/negetives) is suboptimal for proposals of higher IoUs.
(2) the distribution of bounding boxes changes significantly after each iteration.
Usually, there is no benefit beyond applying the same regressoin function twice.
[Cascade R-CNN]
[IoU-Net]
Predict localization confidence
-Two drawbacks without localization confidence:
(1) In nms, the classification scores are typically used as the metric for ranking the proposals. But the localization accuracy is not well correlated with the classification confidence.
(2) The absence of localization confidence makes the widely adopted bounding box regression less interpretable. Bounding box regression may degenerate the localization of input bounding boxes if applied for multiple times
[IoU-Net ECCV2018] Acquisition of Localization Confidence for Accurate Object Detection
[paper] https://arxiv.org/abs/1807.11590
[official code] https://github.com/vacancy/PreciseRoIPooling (PreciseRoIPooling)
[summarization]
-Introduce IoU-Net, which predicts the IoU between detected bounding boxes and their corresponding ground-truth boxes, making the networks aware of the localization criterion.
-Generate bounding boxes and labels for training the IoU-Net by augmenting the ground-truth, instead of taking proposals from RPNs.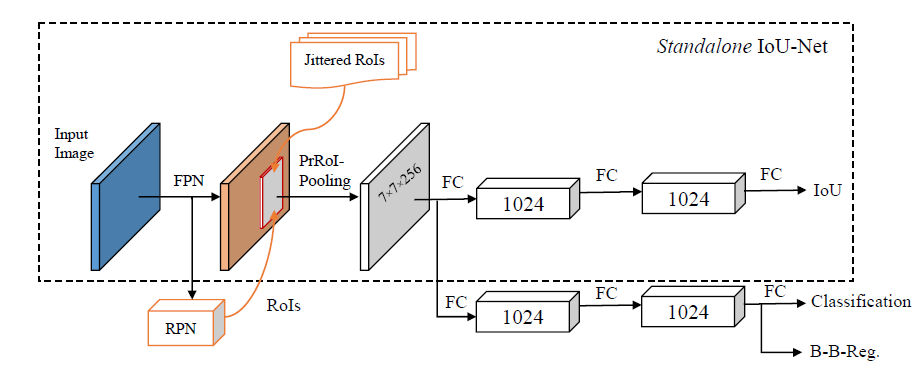
-IoU-guided NMS: Replace classification confidence with the predicted IoU as the ranking keyword in NMS. When a box i eliminates box j, update the classification confidence si of box i by si = max(si; sj )
-New bounding box refinement method: Optimization-based bounding box refinement (on par with traditional regression-based methods.)
-Precise RoI Pooling: It avoids any quantization of coordinates and has a continuous gradient on bounding box coordinates.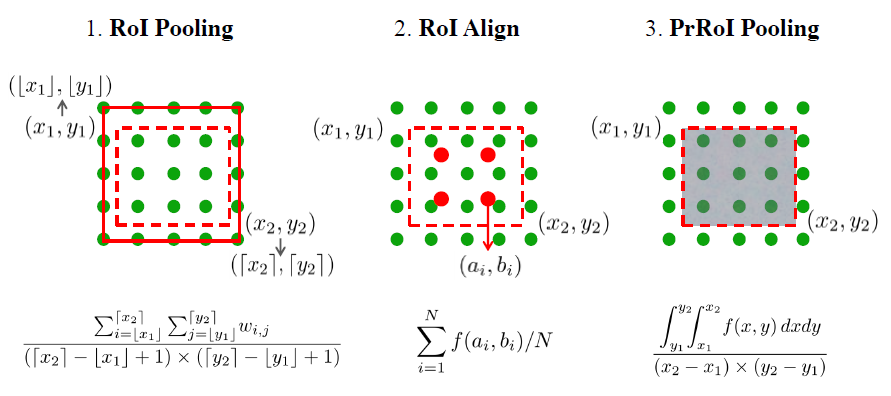
To remove duplicated bounding boxes
Widely-adopted approach: NMS
Modification for NMS
To eliminate high-scored false positives

Learning high quality object detectors
-IoU threshhold(u): is set to determine positives/negetives
When u is high, the positives contain less background, but it is difficult to assemble enough positive training examples. When u is low, a richer and more diversified positive training set is available, but the trained detector has little incentive to reject close false positives.In general, it is very difficult to ask a single classifier to perform uniformly well over all IoU levels.
低IoU threshold对于低IoU的样本有更好的改善,但是对于高IoU的样本就不如高threshold的有用。原因在于不同threshold下样本的分布会不一致,也就导致同一个threshold很难对所有样本都有效。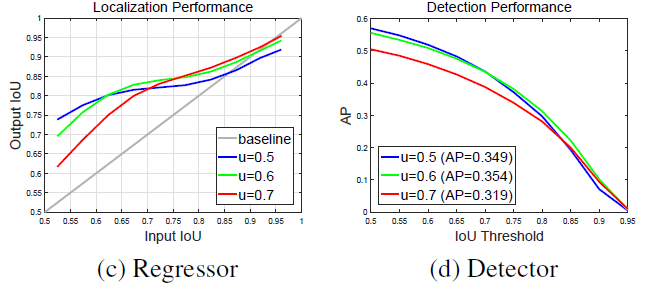
[Cascade RCNN - CVPR2018] Cascade R-CNN: Delving into High Quality Object Detection
[paper] https://arxiv.org/abs/1712.00726
[official code] https://github.com/zhaoweicai/cascade-rcnn
[summarization]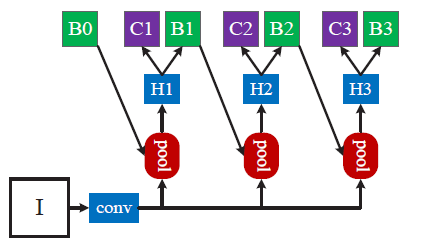
-At each stage t, the R-CNN includes a classifier ht and a regressor ft optimized for IoU threshold ut, where ut > ut−1. This is guaranteed by minimizing the loss
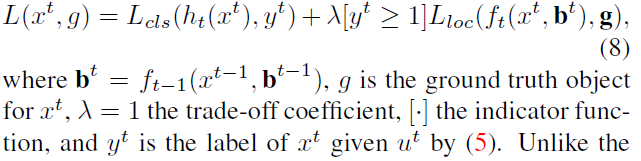
-Cascaded regression is a resampling procedure that changes the distribution of hypotheses to be processed by the different stages. By adjusting bounding boxes, each stage aims to find a good set of close false positives for training the next stage
-A bounding box regressor trained for a certain u tends to produce bounding boxes of higher IoU. Hence, starting from a set of examples (xi, bi), cascade regression successively resamples an example distribution (x′i, b′i) of higher IoU.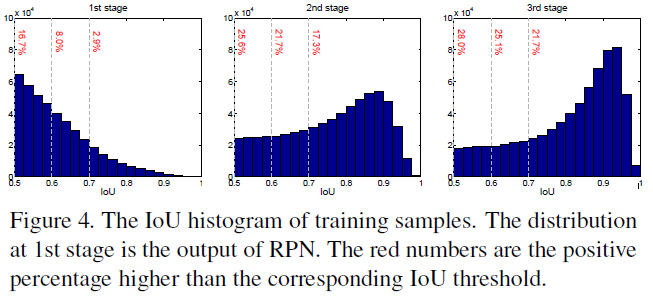
Improve the classification power
(1)Shared feature representation for both classification and localization may not be optimal
(2)joint optimization also leads to possible sub-optimal to balance the goals of multiple tasks and could not directly utilize the full potential on individual tasks;
(3)large receptive fields could lead to inferior classification capacity by introducing redundant context information for small objects.
[DCR - ECCV2018] Revisiting RCNN: On Awakening the Classification Power of Faster RCNN
[paper] https://arxiv.org/abs/1803.06799
[official code] https://github.com/bowenc0221/Decoupled-Classification-Refinement
[summarization]
-Propose Decoupled Classification Refinement to eliminate high-scored false positives and improve the region proposal classification results.
-It takes input from a base classiffier, e.g. the Faster RCNN, and refine the classification results using a RCNN-styled network.
-Adaptive Receptive Field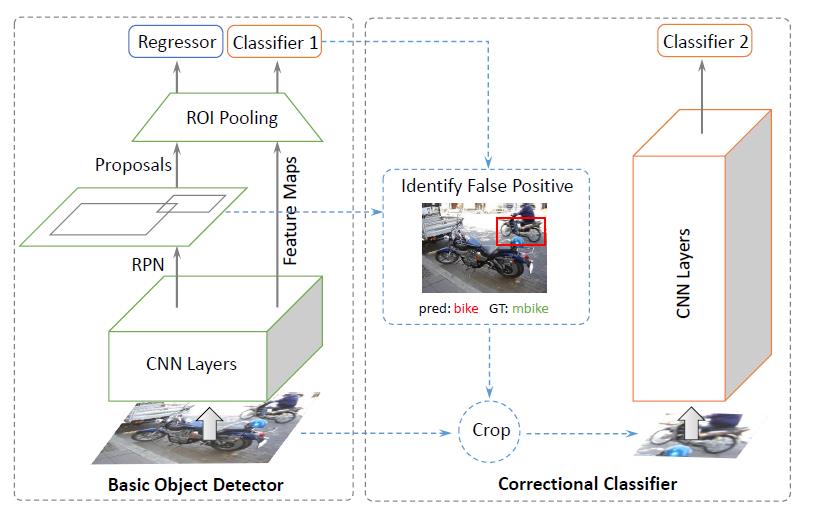
[DCR V2] Decoupled Classification Refinement: Hard False Positive Suppression for Object Detection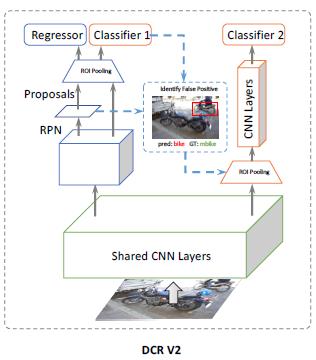
Anchor
Anchors are regression references and classification candidates to predict proposals (for two-stage detectors) or final bounding boxes (for single-stage detectors). Modern object detection pipelines usually begin with a large set of densely distributed anchors.
Two general rules for a reasonable anchor design: (1)Alignment: anchor centers need to be well aligned with feature map pixels. (2)Consistency: the receptive field and semantic scope are consistent in different regions of a feature map, so the scale and shape of anchors across different locations should be consistent.
The uniform anchoring scheme can lead to two difficulties: (1) A neat set of anchors of fixed aspect ratios has to be predefined for different problems. A wrong design may hamper the speed and accuracy of the detector. (2) To maintain a sufficiently high recall for proposals, a large number of anchors are needed, while most of them correspond to false candidates that are irrelevant to the object of interests.
Modify anchor generation scheme
[Guided Anchoring - CVPR2019] Region Proposal by Guided Anchoring
[paper] https://arxiv.org/abs/1901.03278
[official code] https://github.com/open-mmlab/mmdetection
[summarization]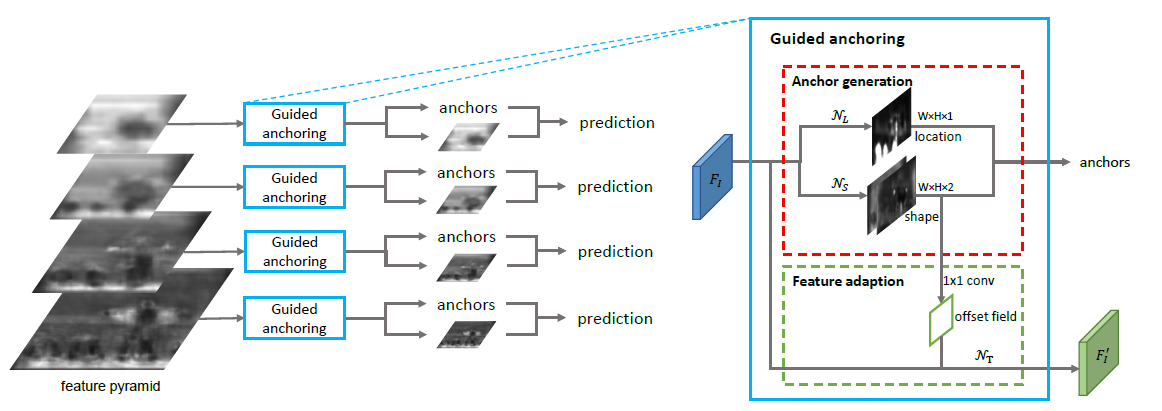
(1)Anchor Location Prediction:
-a 1x1 convolution and an element-wise sigmoid function.
-yields a probability map that indicates the possible locations of the objects.
-selecting those locations whose corresponding probability values are above a predefined threshold.
-use masked convolution when inference
-define center/ignore/outside region, use focal loss when training
(2)Anchor Shape Prediction:
-predict the best shape (w; h) for each location.
-a 1x1 convolutional layer that yields a two-channel map that contains the values of dw and dh, an element-wise transform layer that implements Eq.(2).
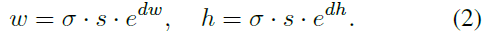
-when training, sample some common values of w and h, calculate the IoU of these sampled anchors with gt, use the maximum. use bounded iou loss.
(3)Anchor Guided Feature Adaptation
-Ideally, the feature for a large anchor should encode the content over a large region, while those for small anchors should have smaller scopes accordingly.
-first predict an offset field from the output of anchor shape prediction branch, and then apply 3x3 deformable convolution to the original feature map with the offsets.
(4)The Use of High quality Proposals
-set a higher positive/negative threshold and use fewer samples when training detectors with GA-RPN compared to RPN.
The way to extract fixed-length feature vector
RoI Pooling [Fast R-CNN]
RoI Align [Mask R-CNN]
Precise RoI Pooling [IoU-Net]
To accommodate geometric variations
[DCN - ICCV2017] Deformable Convolutional Networks
[summarization]
-CNNs are inherently limited to model large, unknown transformations. There lacks internal
mechanisms to handle the geometric transformations.
-Deformable convolution
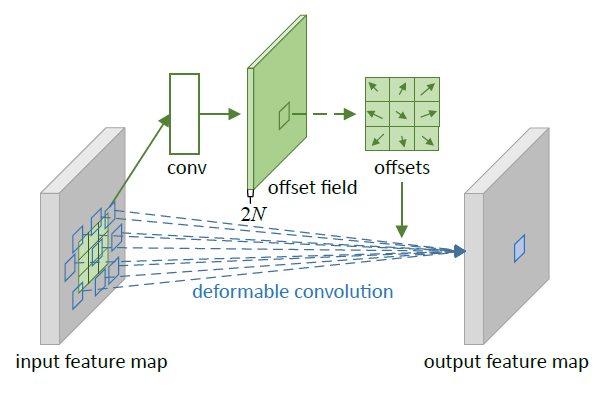
The offsets are obtained by applying a convolutional layer over the same input feature map. The output offset fields have the same spatial resolution with the input feature map. The channel dimension 2N corresponds to N 2D offsets.
-Deformable RoI Pooling
[DCNv2 - 1811] Deformable ConvNets v2: More Deformable, Better Results
[summarization]
-Stacking More Deformable Conv Layers
-Modulated Deformable Modules
Not only adjust offsets in perceiving input features, but also modulate the input feature amplitudes from different spatial locations / bins.
Improvement for One Stage Framework
Foreground-background class imbalance problem
Class imbalance is addressed in R-CNN-like detectors by a two-stage cascade and sampling heuristics. The proposal stage (e.g., Selective Search, EdgeBoxes, DeepMask, RPN) rapidly narrows down the number of candidate object locations to a small number (e.g., 1-2k), filtering out most background samples. In the second classification stage, sampling heuristics, such as a fixed foreground-to-background ratio (1:3), or online hard example mining (OHEM), are performed to maintain a manageable balance between foreground and background.
In contrast, a one-stage detector must process a much larger set of candidate object locations regularly sampled across an image. In practice this often amounts to enumerating ~100k locations that densely cover spatial positions, scales, and aspect ratios. While similar sampling heuristics may also be applied, they are inefficient as the training procedure is still dominated by easily classified background examples.
New classification loss function
[Focal Loss - ICCV2017] Focal Loss for Dense Object Detection
[paper]
[summarization]
-Identify class imbalance during training as the main obstacle impeding one-stage detector from achieving state-of-the-art accuracy.
-Focal Loss
Dynamically scaled cross entropy loss: down-weight the contribution of easy examples during training and rapidly focus the model on hard examples.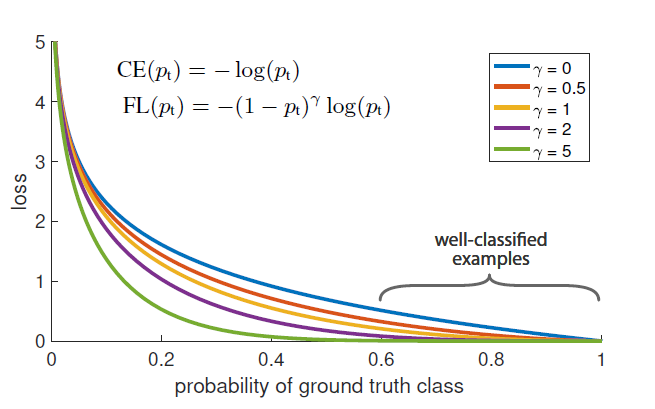
Consider the cross entropy (CE) loss for binary classification: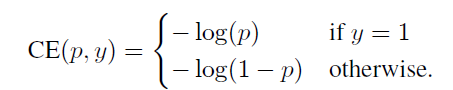
Rewrite it by pt: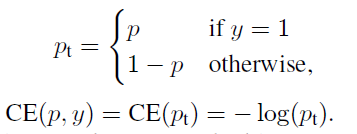
Define the focal loss as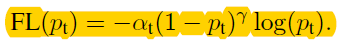
-RetinaNet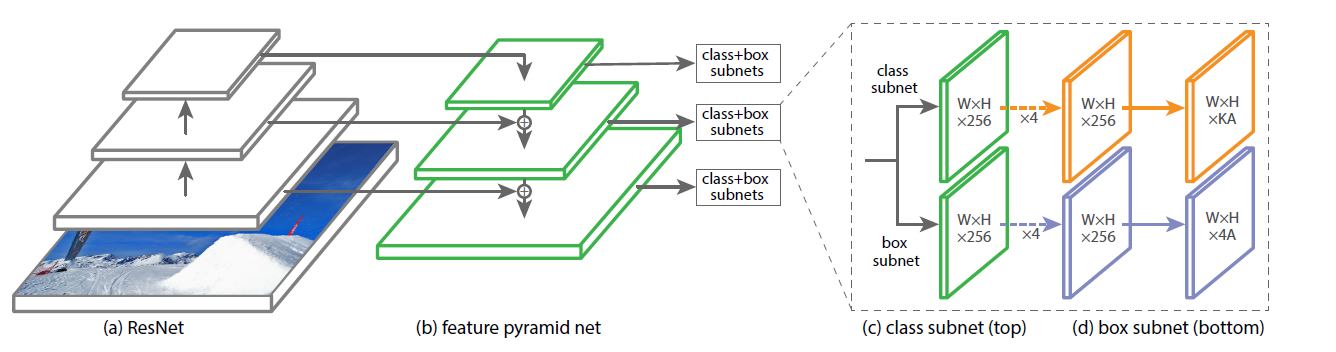
To alleviate the problems arising from scale variation and small object instances
Construct feature pyramid
[PFPNet - ECCV2018] Parallel Feature Pyramid Network for Object Detection
[paper]
[summarization]
-Employ the SPP module to generate pyramid-shaped feature maps via widening the network width instead of increasing its depth.
-SSD / RefineDet VGG16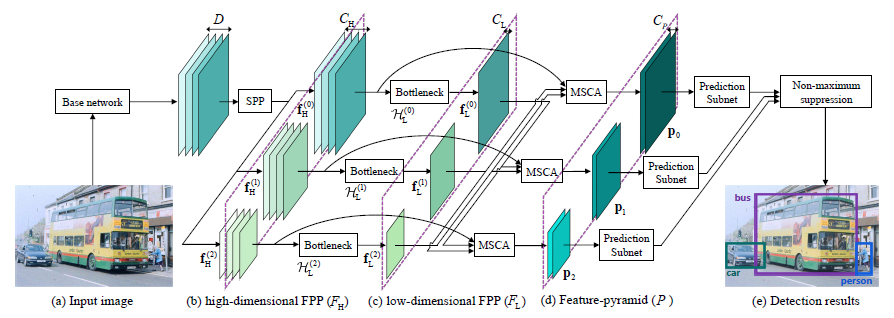
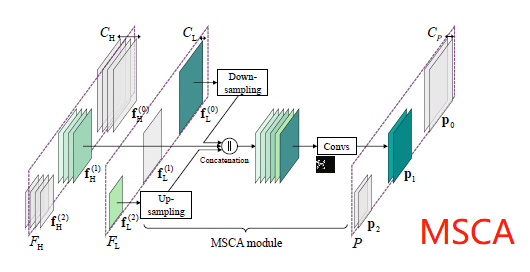
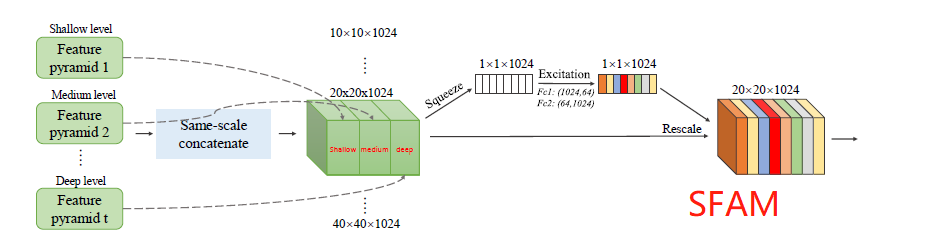
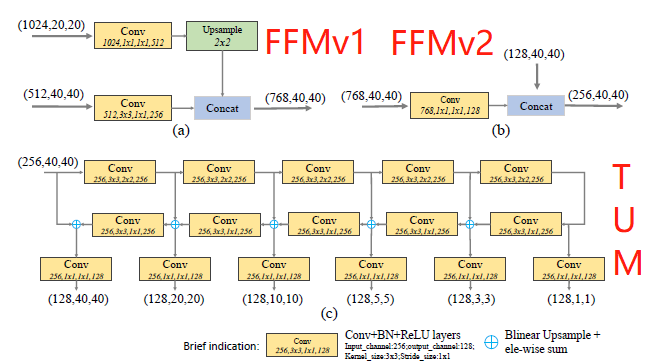
[M2Det - AAAI2019] M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network
[paper] https://arxiv.org/abs/1811.04533
[official code] https://github.com/qijiezhao/M2Det
[summarization]
-For previous feature pyramid method, each feature map (used for detecting objects in a specific range of size) in the pyramid mainly or only consists of single-level features will result in suboptimal detection performance.
-Multi-Level Feature Pyramid Network (MLFPN).
-Based on SSD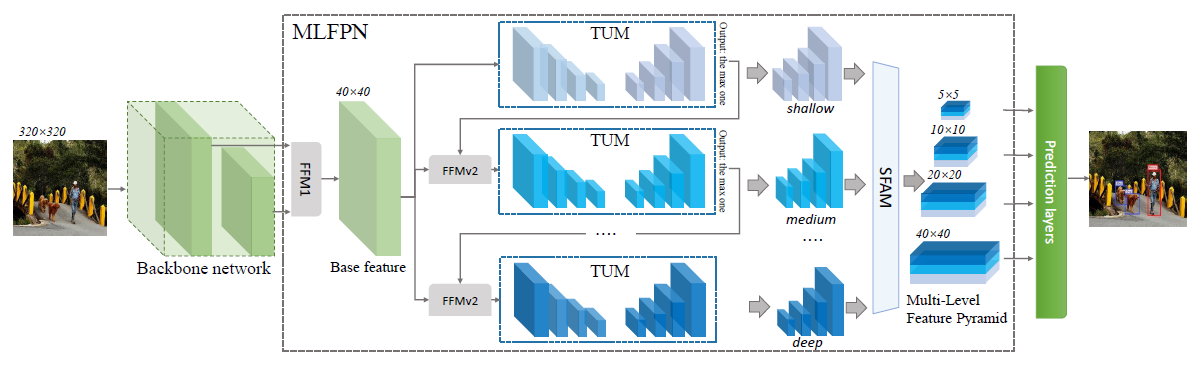
Anchor(default box)
In short, anchor method suggests dividing the box space (including position, size, class, etc.) into discrete bins (not necessarily disjoint) and generating each object box via the anchor function defined in the corresponding bin.
Currently most of the detectors model anchors via enumeration, i.e. predefining a number of anchor boxes with all kinds of positions, sizes and class labels, which leads to the following issues.First, anchor boxes need careful design (chosen by handcraft or statistical methods like clustering). Second, predefined anchor functions may cause too many parameters.
[MetaAnchor - NIPS2018] MetaAnchor: Learning to Detect Objects with Customized Anchor
[paper] https://arxiv.org/abs/1807.00980
[summarization]
Anchor free method
Other improvement
Dataset
Framework
[mmdetction] https://github.com/open-mmlab/mmdetection
[OneStageDet] https://github.com/TencentYoutuResearch/ObjectDetection-OneStageDet
[Detectron] https://github.com/facebookresearch/Detectron