Sematic Segmentation
[FCN - CVPR2015]
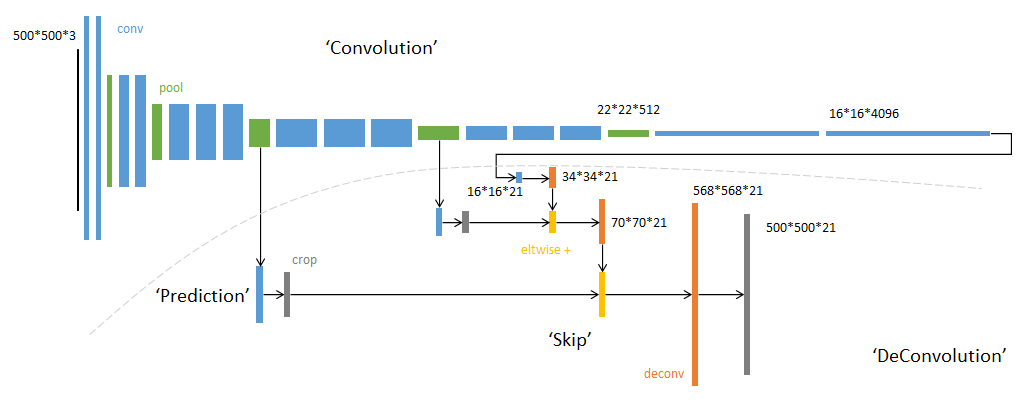
-不含全连接层(fc)的全卷积(fully conv)网络。可适应任意尺寸输入。
-增大数据尺寸的反卷积(deconv)层。能够输出精细的结果。
-结合不同深度层结果的跳级(skip)结构。同时确保鲁棒性和精确性。
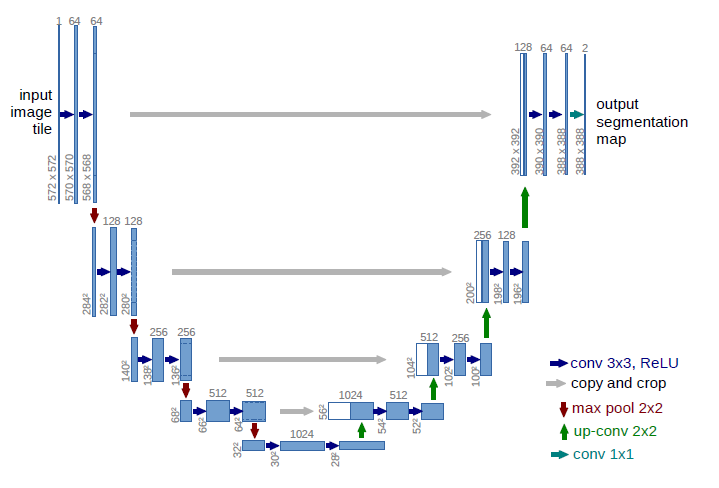
[U-Net - MICCAI2015]
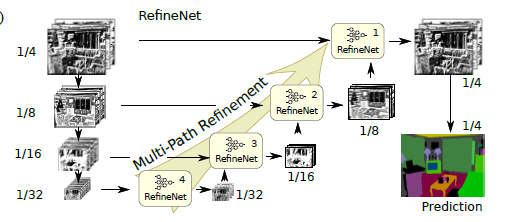
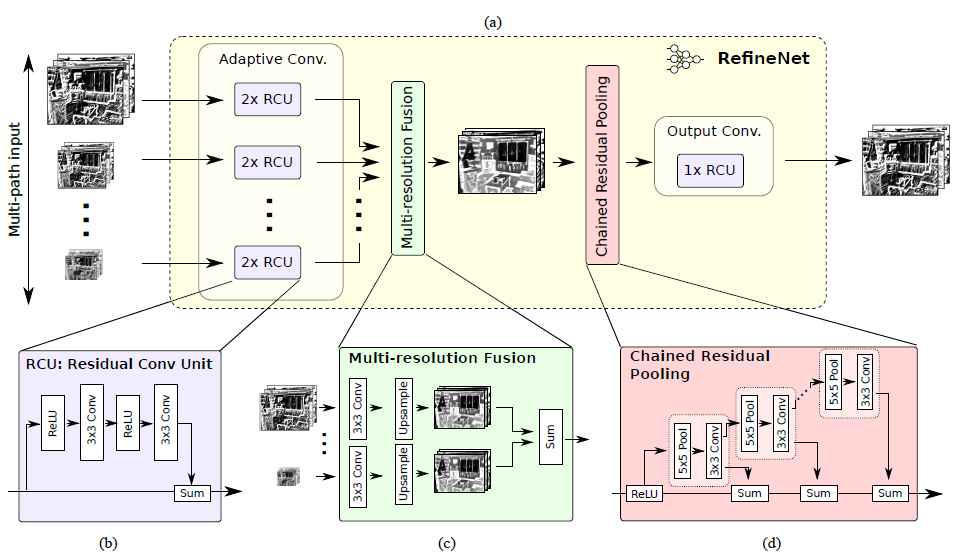
[RefineNet - CVPR2017]
-The deconvolution operations are not able to recover the low-level visual features which are lost after the down-sampling operation in the convolution forward stage
-Dilated convolutions introduce a coarse sub-sampling of features, which potentially leads to a loss of important details
-RefineNet provides a generic means to fuse coarse high-level semantic features with finer-grained low-level features to generate high-resolution semantic feature maps.
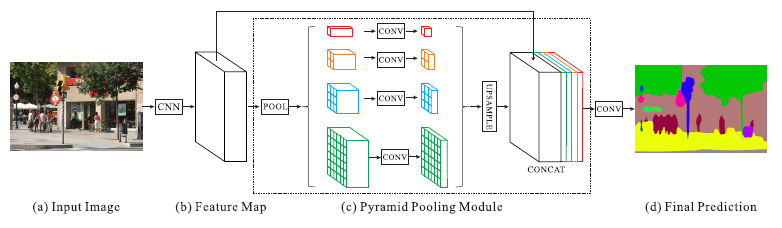
[PSPNet - CVPR2017]
-Current FCN based model is lack of suitable strategy to utilize global scene category clues.
-Global context information along with sub-region context is helpful in this regard to distinguish among various categories.
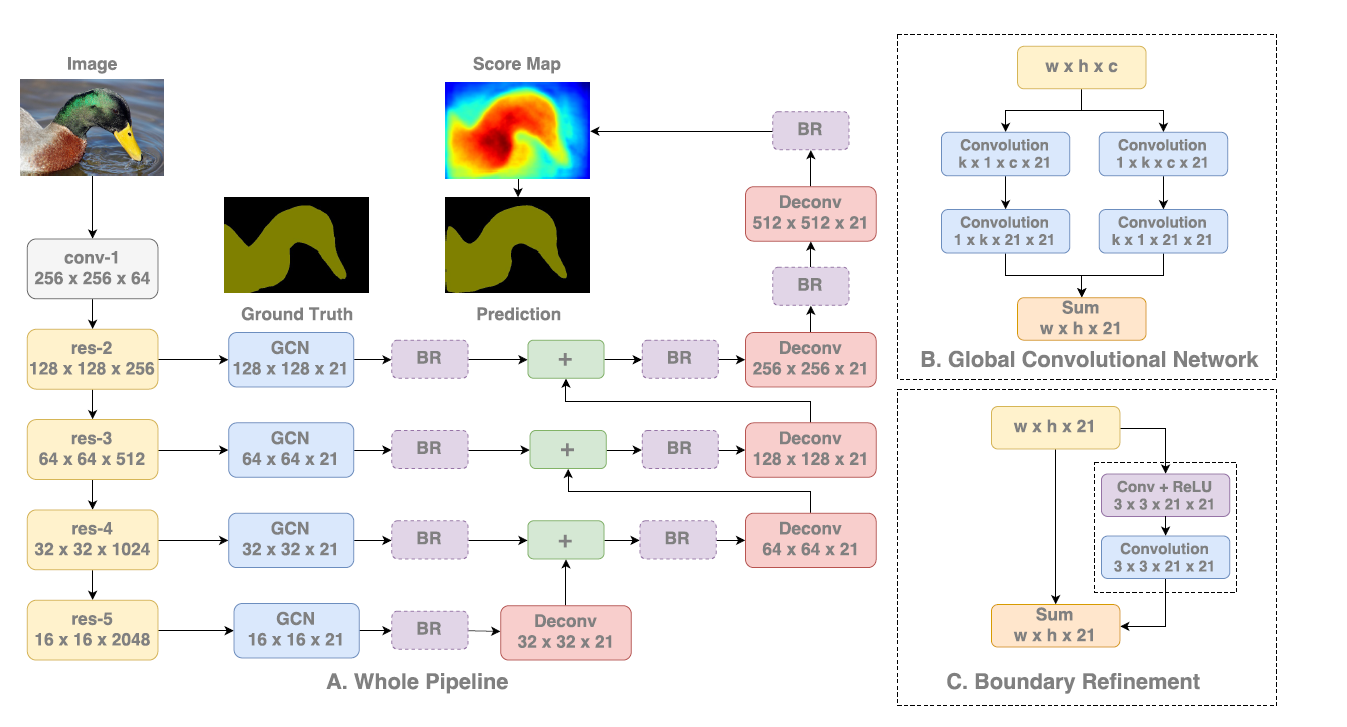
[GCN - CVPR2017] Large Kernel Matters——Improve Semantic Segmentation by Global Convolutional Network
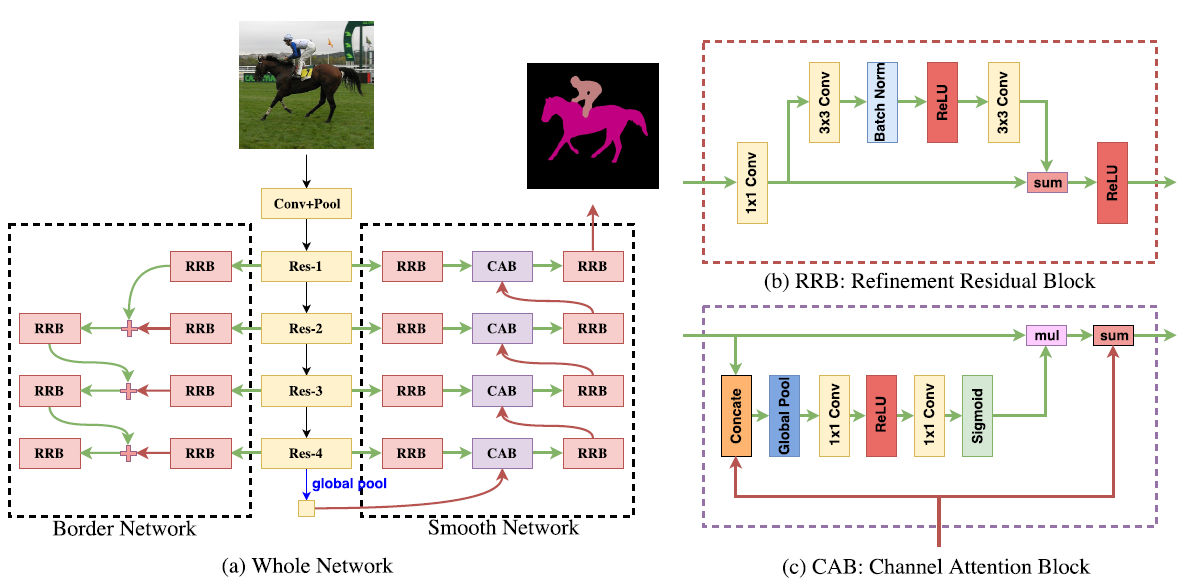
[DFN - CVPR2018] Learning a Discriminative Feature Network for Semantic Segmentation
[BiSeNet - ECCV2018] BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation
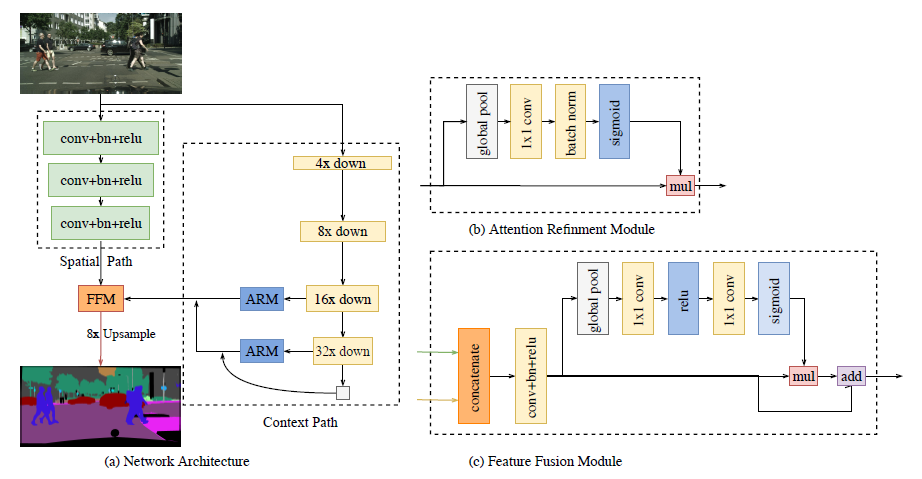
-Spatial Path (SP) and Context Path (CP). As their names imply, the two components are devised to confront with the loss of spatial information and shrinkage of receptive field respectively.
-SP: three layers, each layer includes a convolution with stride = 2, followed by batch normalization and ReLU.
-CP: utilizes lightweight model and global average pooling to provide large receptive fi eld
-loss function:
[ICNet - ECCV2018] ICNet for Real-Time Semantic Segmentation on High-Resolution Images
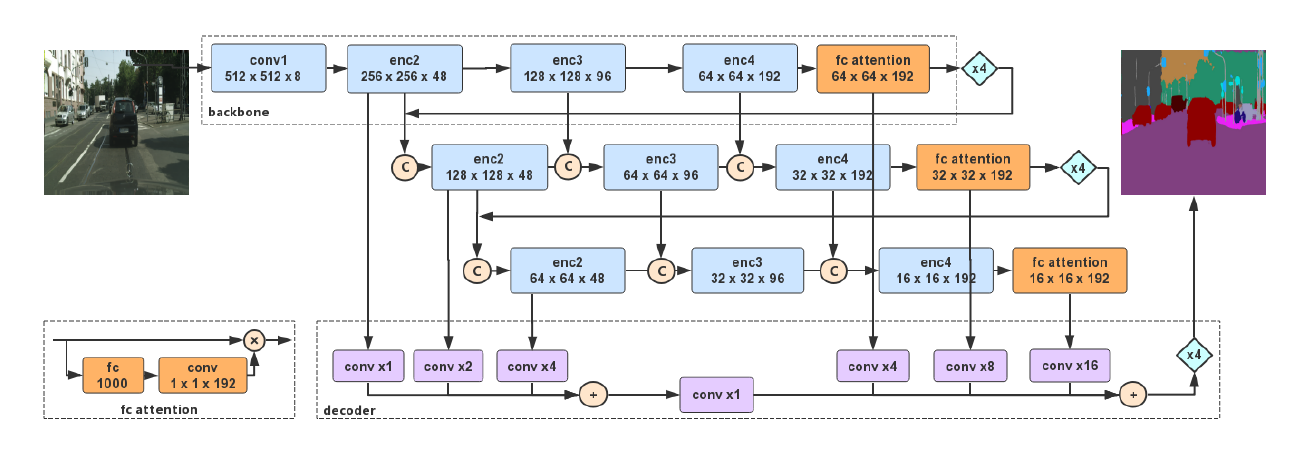
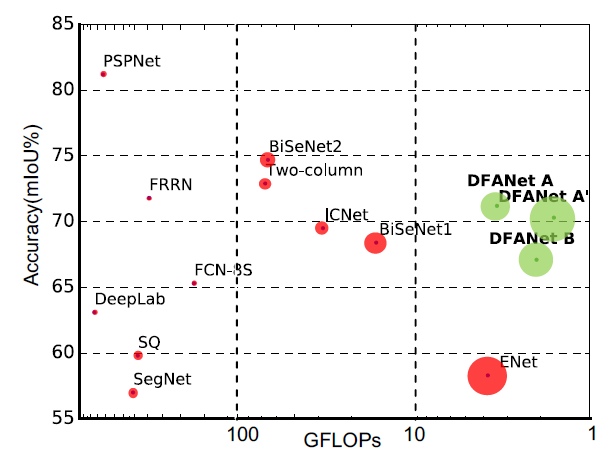
[DFANet - CVPR2019] DFANet: Deep Feature Aggregation for Real-Time Semantic Segmentation
[DeepLabv1 - ICLR2015]
-Atrous Convolution
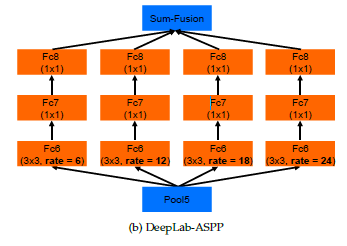
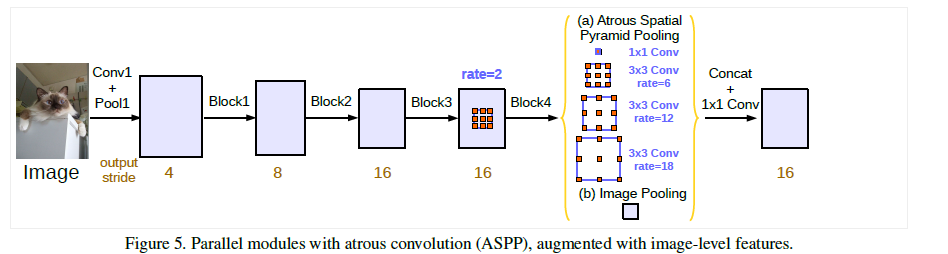
[DeepLabv2]
-Atrous Spatial Pyramid Pooling (ASPP)
[DeepLabv3]
[DeepLabv3+ - ECCV2018]

“Attention” in Segmentation
[NLNet - CVPR2018] Non-local Neural Networks
-Capturing long-range dependencies is of central importance in deep neural networks. Intuitively, a non-local operation computes the response at a position as a weighted sum of the features at all positions in the input feature maps.
-Generic non-local operation:
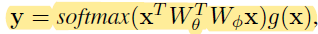
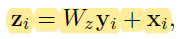
-HWxHW与HWx512做矩阵乘,前一个可以理解为每一行是一个点的f, 然后与512维中每个点相乘,对于每个通道上,用的f值是一样的,可以理解为spatial attention。
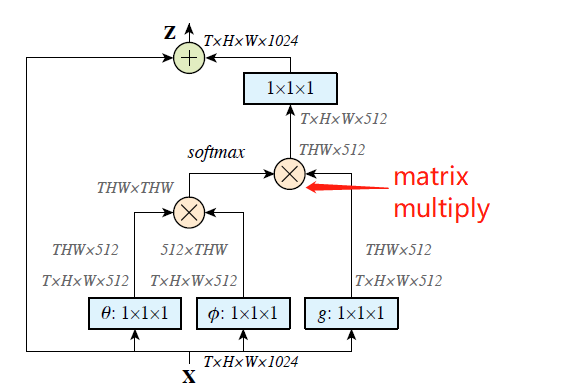
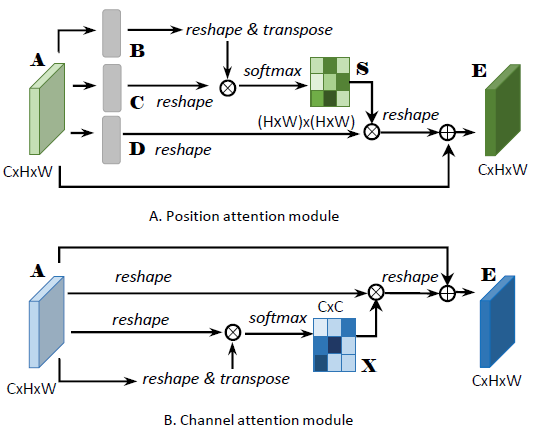
[DANet - CVPR2019] Dual Attention Network for Scene Segmentation
-Introduces a self-attention mechanism to capture features dependencies in the spatial and channel dimensions
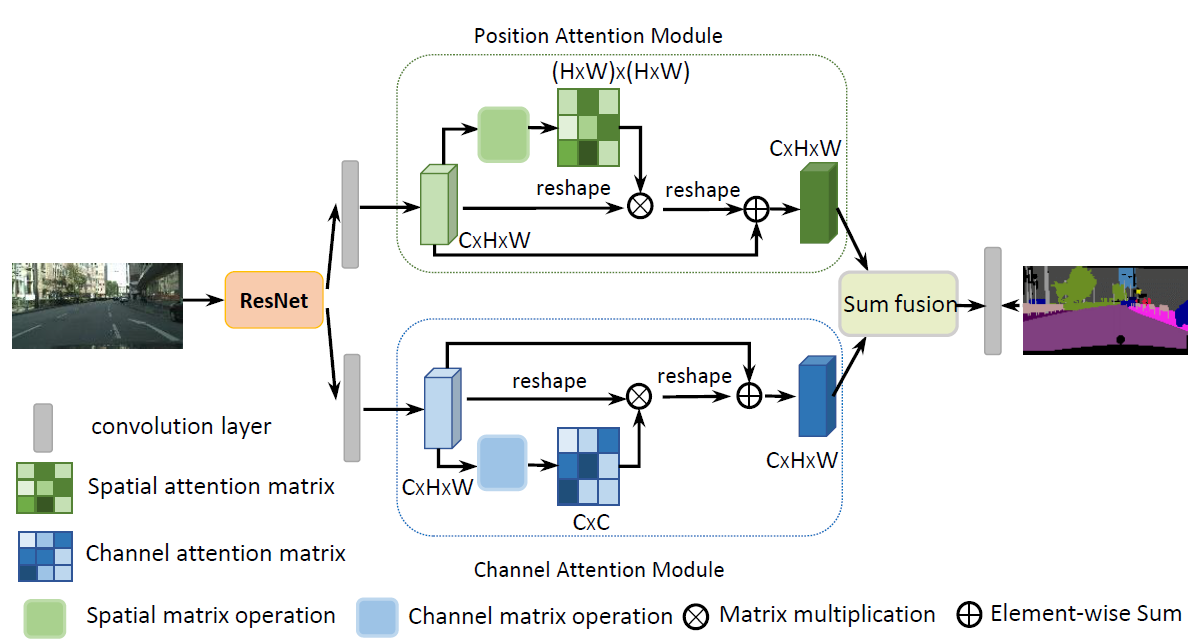

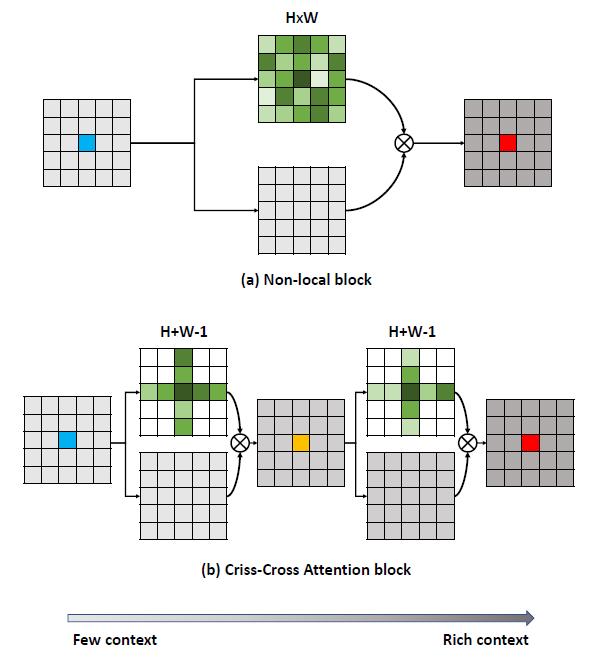
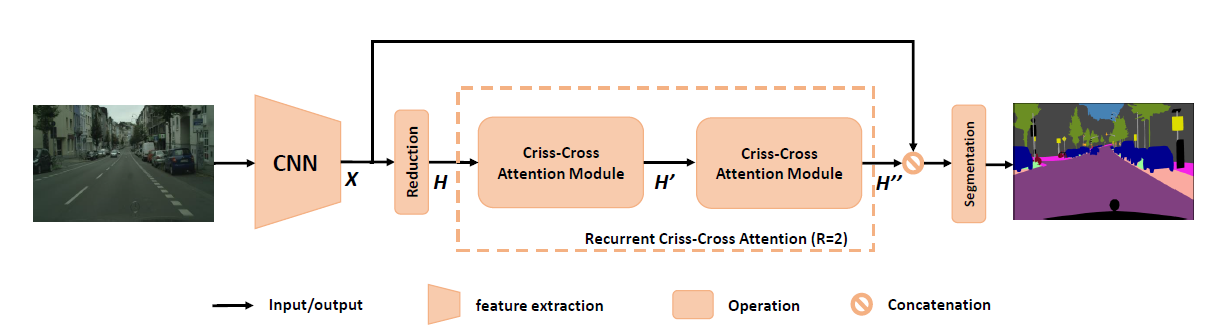
[CCNet - ICCV2019] CCNet: Criss-Cross Attention for Semantic Segmentation
-The current no-local operation, can be alternatively replaced by two consecutive criss-cross operations, in which each one only has sparse connections (H + W - 1) for each position in the feature maps. By serially stacking two criss-cross attention modules, it can collect contextual information from all pixels. The decomposition greatly reduce the complexity in time and space from O((HxW)x(HxW)) to O((HxW)x(H +W - 1)).
-The details of criss-cross attention module: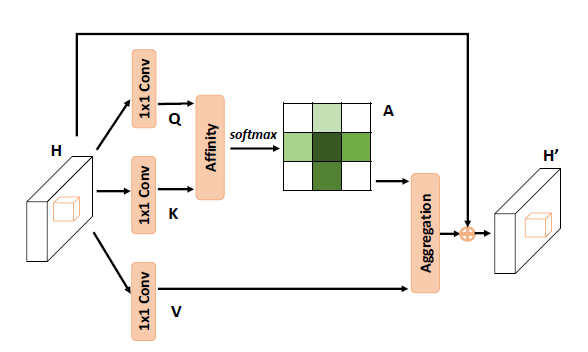

-