PSNR Oriented Approach
[SRCNN - ECCV2014] Learning a Deep Convolutional Network for Image Super-Resolution
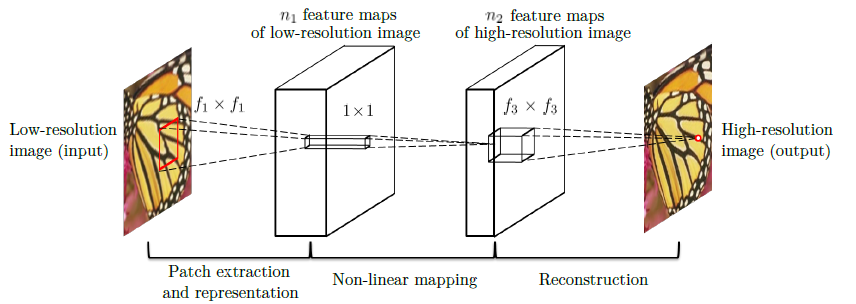
-The training data set is synthesized by extracting nonoverlapping dense patches of size 32x32 from the HR images. The LR input patches are first downsampled and then upsampled using bicubic interpolation having the same size as the high-resolution output image.
-MSE loss
[VDSR - CVPR2016] Accurate Image Super-Resolution Using Very Deep Convolutional Networks
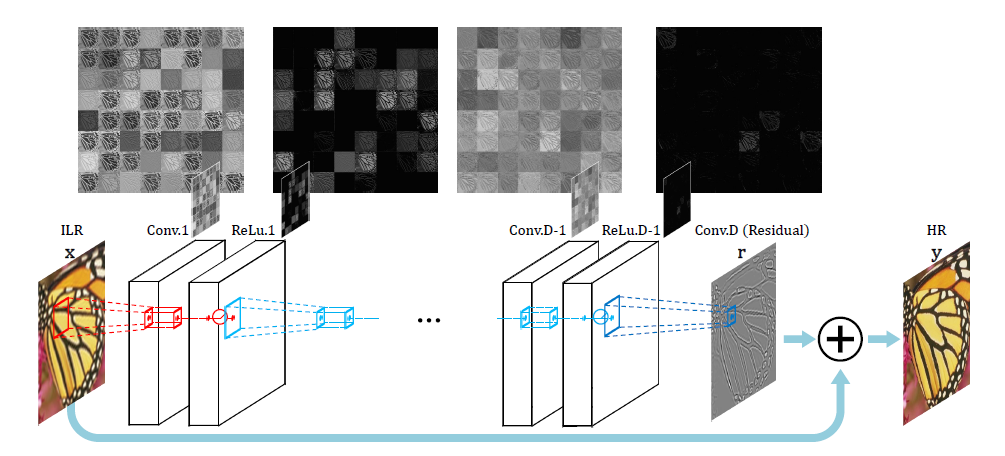
-VGG
-To speed-up the training: (1) learn a residual mapping that generates the difference between the HR and LR image instead of directly generating a HR image. (2) gradients are clipped with in the range [-θ, θ]. These allow very high learning rates.
[ESPCN - CVPR2016] Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network
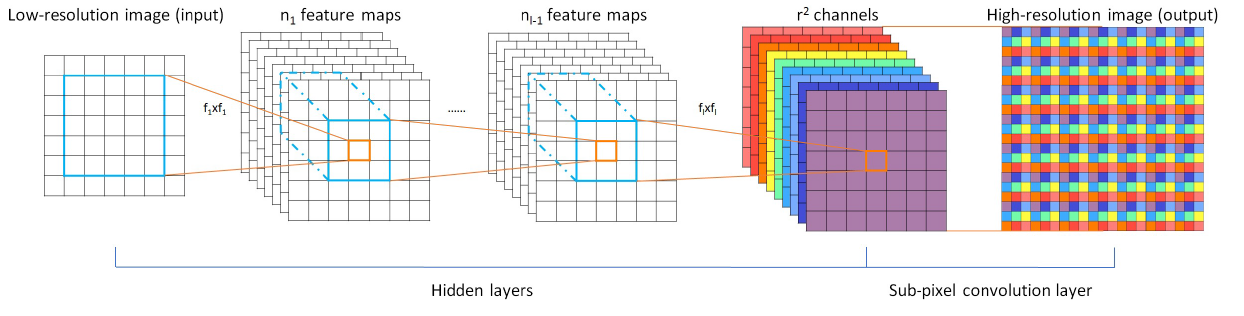
-Propose an efficient sub-pixel convolution layer to learn the upscaling operation for image and video super-resolution.
-Sub-pixel convolution : https://blog.csdn.net/bbbeoy/article/details/81085652
First, use a convolution outputs H x W x Crr. Second, use periodic shuffling to rearange it to Hr x Wr x C
[DRCN - CVPR2016] Deeply-Recursive Convolutional Network for Image Super-Resolution
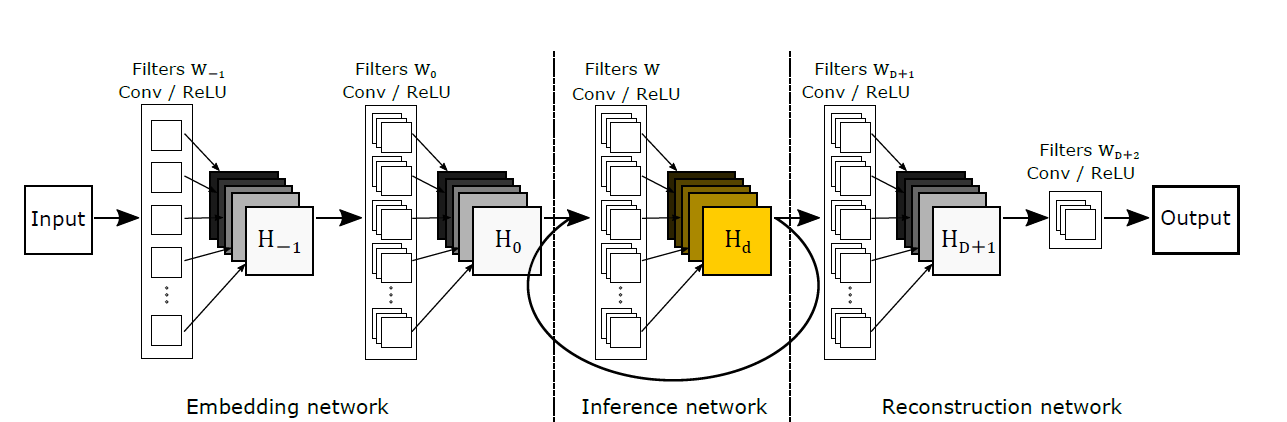
-Supervise all recursions in order to alleviate the effect of vanishing/exploding gradients.
-Add a layer skip from input to the reconstruction net.
[FSRCNN - ECCV2016] Accelerating the Super-Resolution Convolutional Neural Network
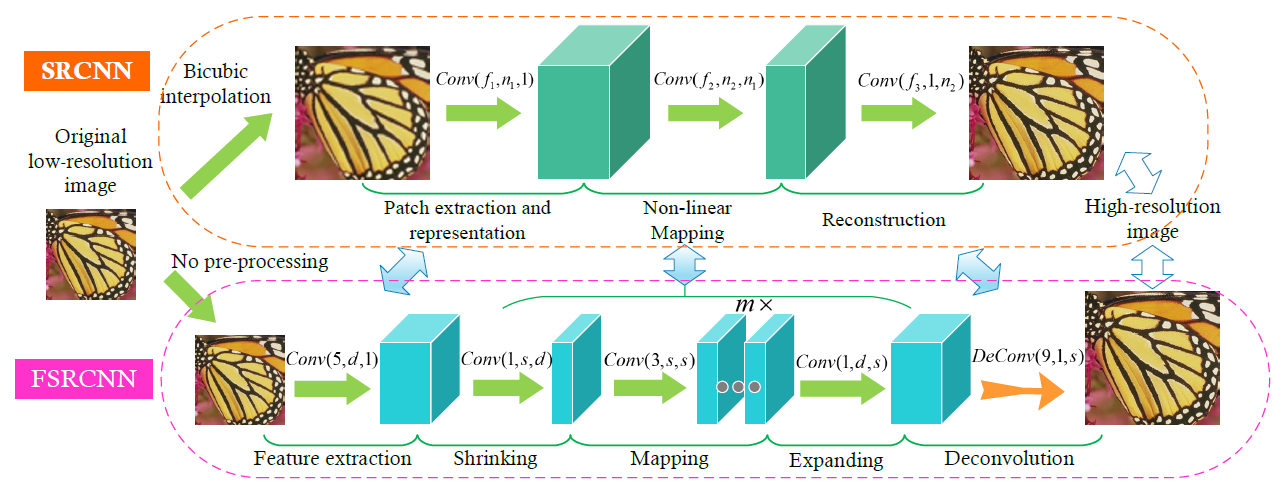
-Use deconvolution as a post-upsamling step instead of upsampling the original LR image as a pre-processing step.
-Use PReLU instead of ReLU.
-Use the 91-image dataset [1] with another 100 images collected from the internet. Data augmentation such as rotation, flipping, and scaling is also employed to increase the number
of images by 19 times.
[1] J. Yang, J.Wright, T. S. Huang, and Y. Ma, “Image super-resolution via sparse representation,” TIP, 2010.
[RED-Net - NIPS2016] Image Restoration Using Convolutional Auto-encoders with Symmetric Skip Connections
[LapSRN - CVPR2017] Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution
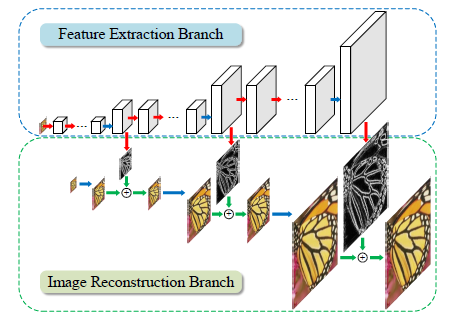
-Progressively predicts residual images at log2(S) levels where S is the scale factor.
-Loss function:
-3x3conv, 4x4deconv, lrelu.
[DRRN - CVPR2017] Image Super-Resolution via Deep Recursive Residual Network
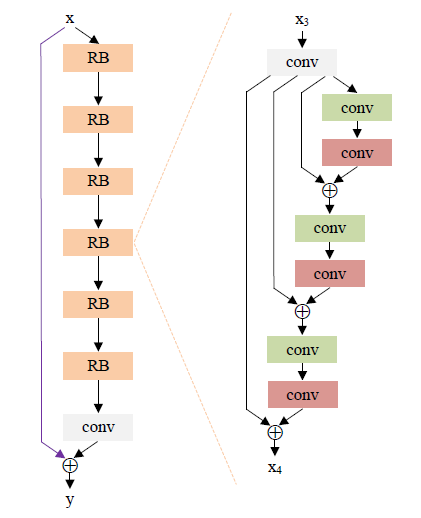
-Global and local residual learning
-Recursive block consisting of several residual units, and the weight set is shared among these residual units.
-For one block, a multi-path structure is used and all the residual units share the same input for the identity branch.
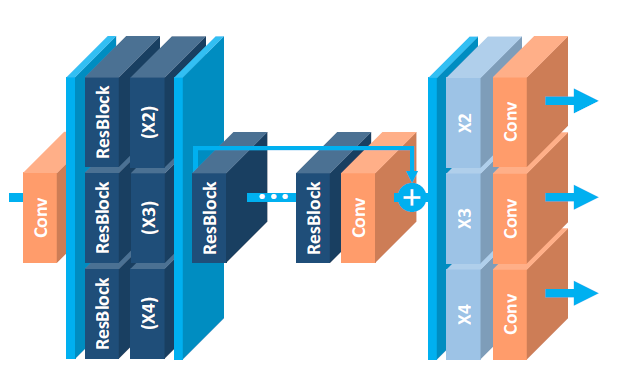
[EDSR - CVPR2017W] Enhanced Deep Residual Networks for Single Image Super-Resolution
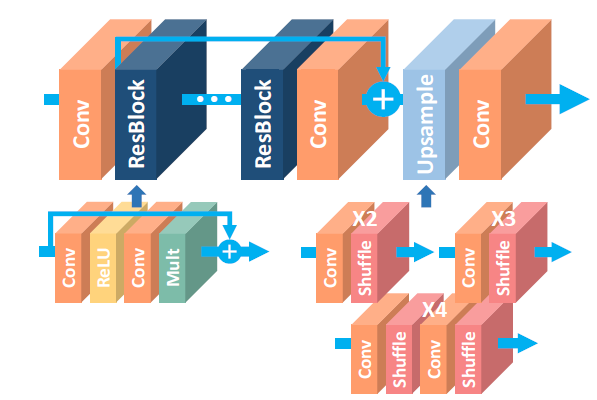
-Modify SRResNet:
(1) Remove Batch Normalization layers (from each residual block) and ReLU activation (outside residual blocks). Since batch normalization layers normalize the features, they get rid of range flexibility from networks by normalizing the features. Furthermore, GPU memory usage is also sufficiently reduced since the batch normalization layers consume the same amount of memory as the preceding convolutional layers. Consequently, we can build up a larger model.
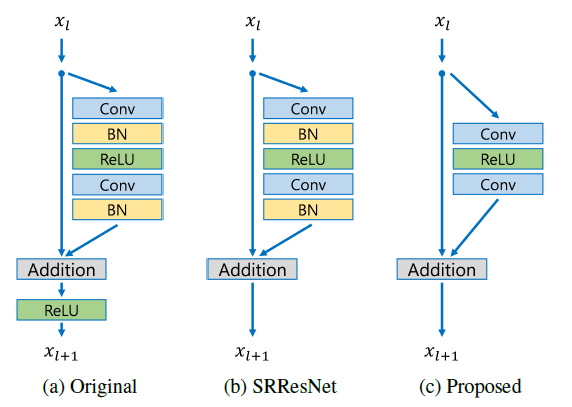
(2) Increasing F(the number of feature channels) instead of B(thenumber of layers) can maximize the model capacity when considering limited computational resources. Use residual scaling to stabilize the training procedure. In EDSR, set B = 32, F = 256, scaling factor=0.1.
-When training our model for upsampling factor x3 and x4, we initialize the model parameters with pre-trained x2 network.
-MDSR (Multi scale model) (B = 80 and F = 64)
-L1 loss provides better convergence than L2.
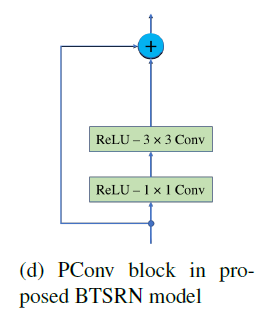
[BTSRN - CVPR2017W] Balanced Two-Stage Residual Networks for Image Super-Resolution
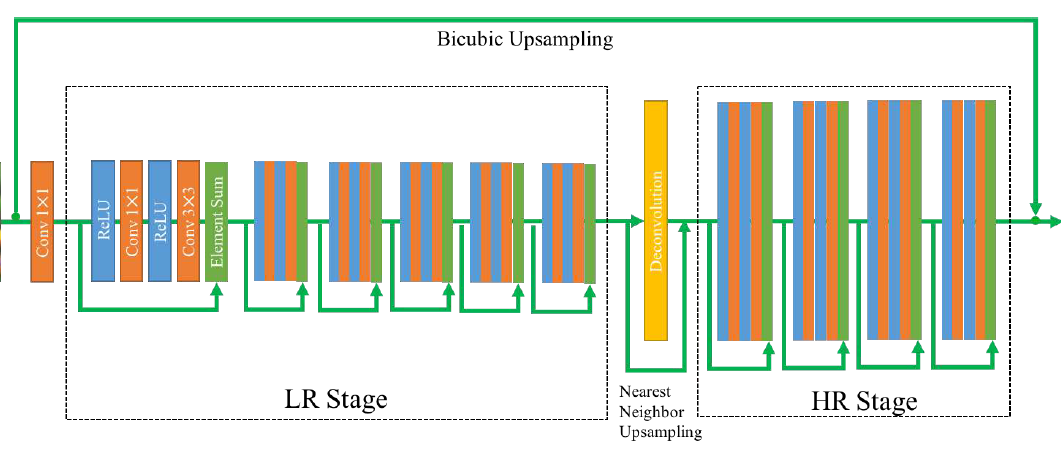
-Only 10 residual blocks to ensure the efficiency. (6 for lr stage, 4 for hr stage)
-For the up-sampling layers, the element sum of nearest neighbor up-sampling and deconvolution is employed. To reduce the artifacts, the stride and size of kernels are equal to scaling factor for x2 and x3, and two x2 up-sampling are applied for x4 scaling.
-Batch normalization is not suitable for super-resolution task. Because super-resolution is a regressing task, the target outputs are highly correlated to inputs first order statistics, while batch normalization makes the networks invariant to data re-centering and re-scaling.
-Predict the residual images. L2 loss.
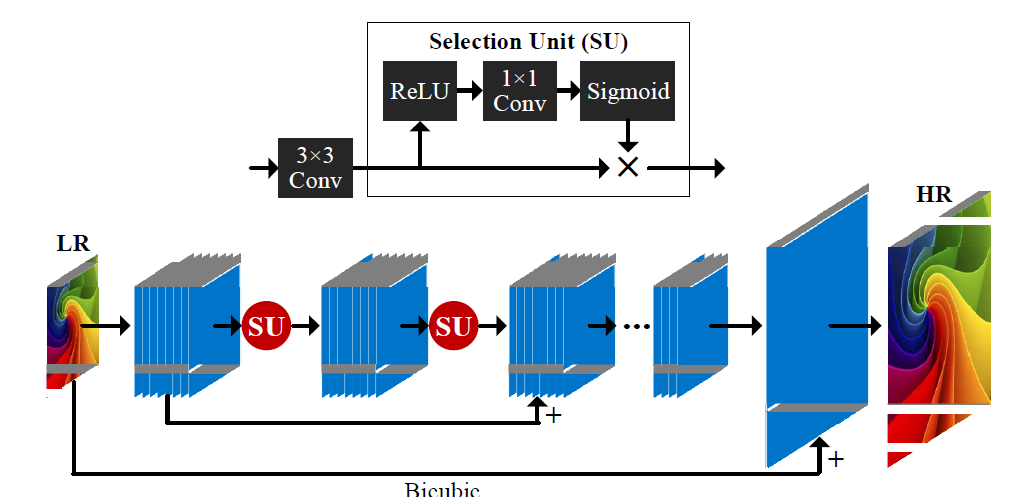
[SelNet - CVPR2017W] A Deep Convolutional Neural Network with Selection Units for Super-Resolution
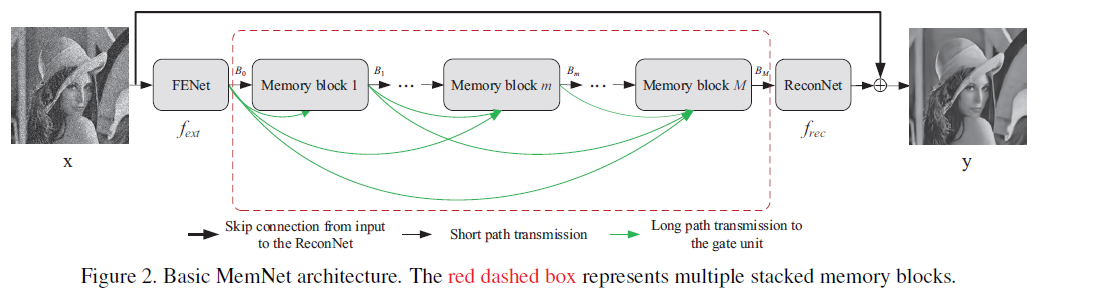
[MemNet - ICCV2017] MemNet: A Persistent Memory Network for Image Restoration
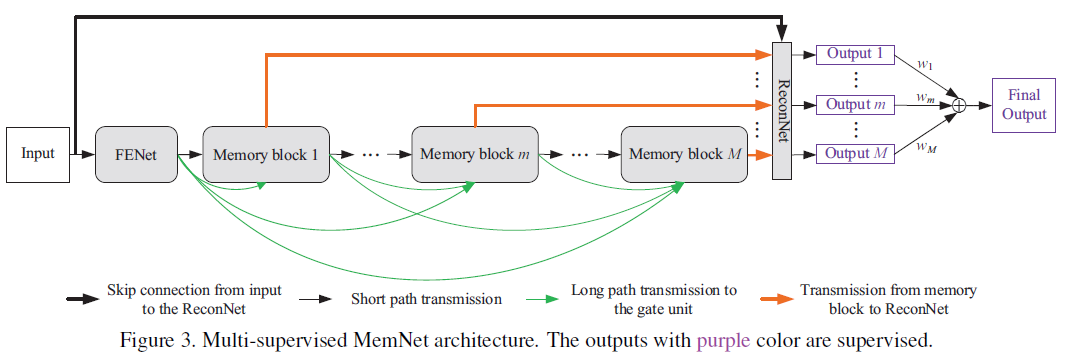
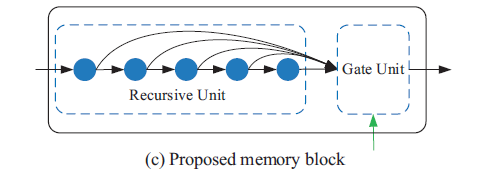
-Gate unit: 1x1conv
[SRDenseNet - ICCV2017] Image Super-Resolution Using Dense Skip Connections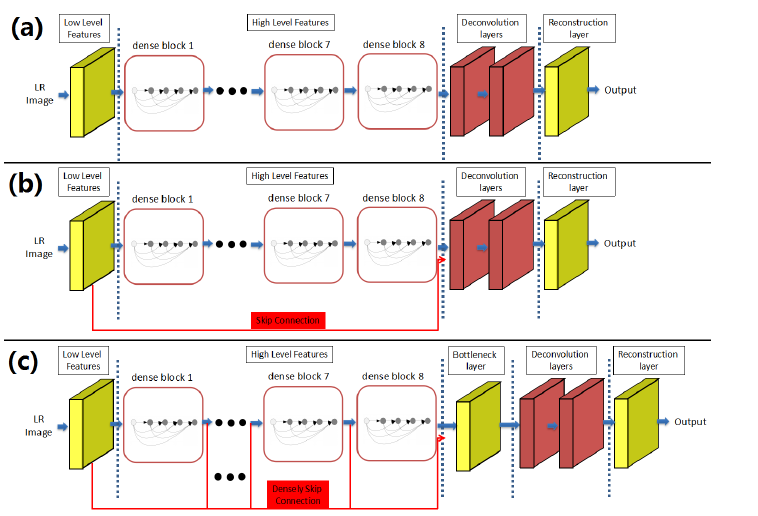
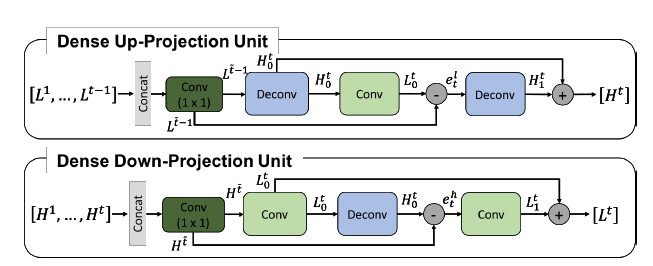
[RDN - CVPR2018] Residual Dense Network for Image Super-Resolution
加一点MemNet,加一点SRDenseNet
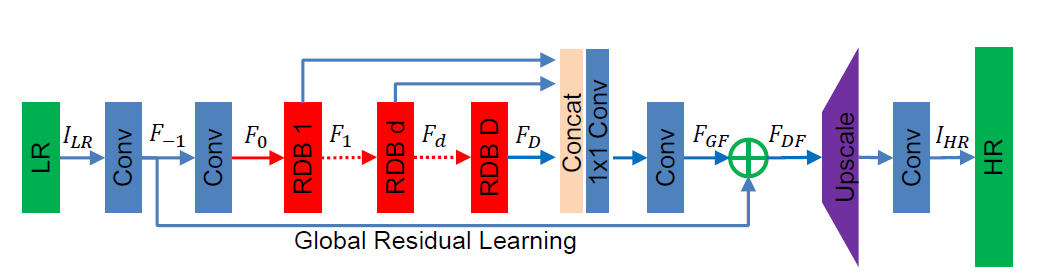
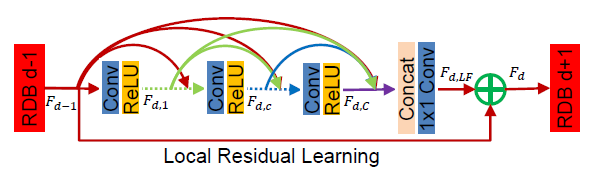
-l1 loss which has been demonstrated to be more powerful for performance and convergence.
[DBPN - CVPR2018] Deep Back-Projection Networks For Super-Resolution
-DBPN: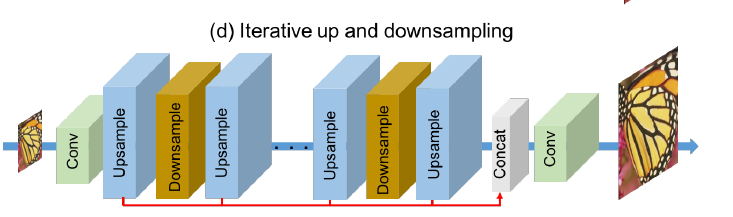
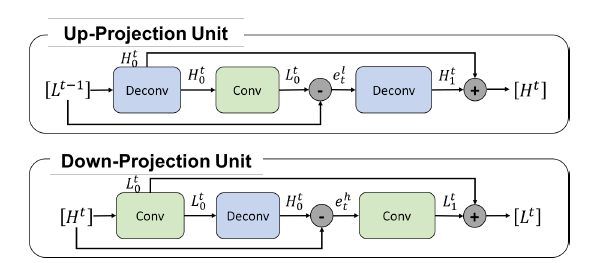
-D-DBPN: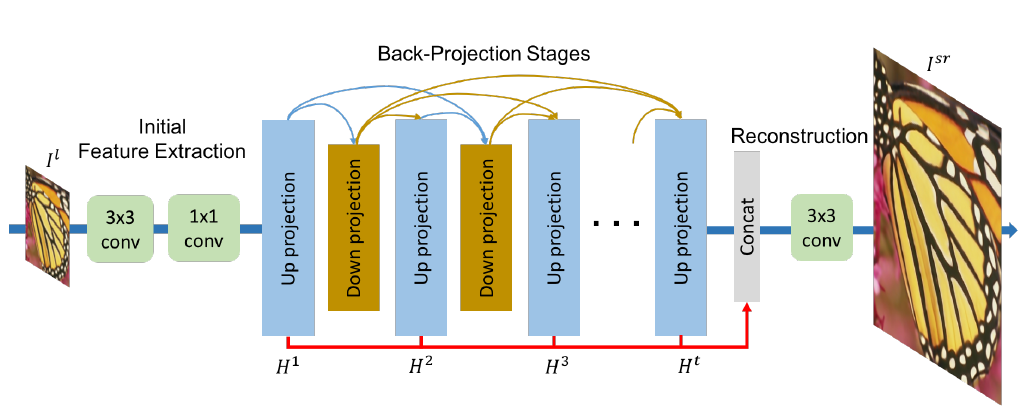
-Avoid dropout and batch norm, use 1 x 1 convolution layer as feature pooling and dimensional
reduction instead.
-The projection unit uses large sized filters such as 8 x 8 and 12 x 12. In other existing networks, the use of largesized filter is avoided because it slows down the convergence speed and might produce sub-optimal results. However, iterative utilization of our projection units enables the network to suppress this limitation and to perform better performance on large scaling factor even with shallow net works.
[IDN - CVPR2018] Fast and Accurate Single Image Super-Resolution via Information Distillation Network
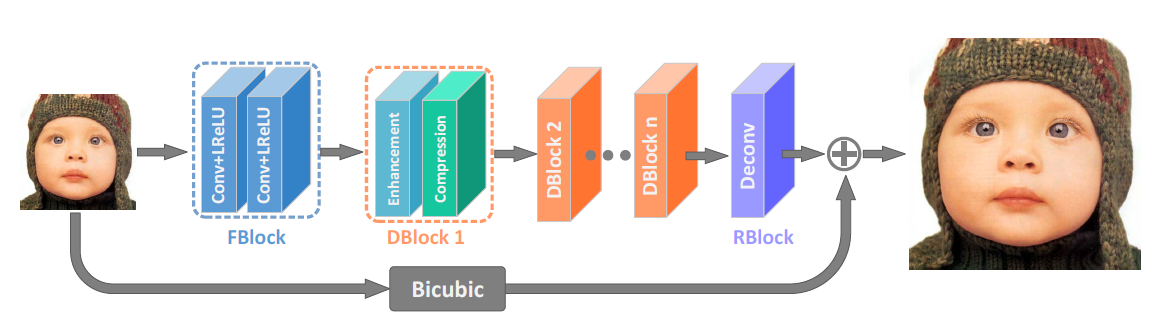
-Enhancement unit (each of convs is followed by LReLU)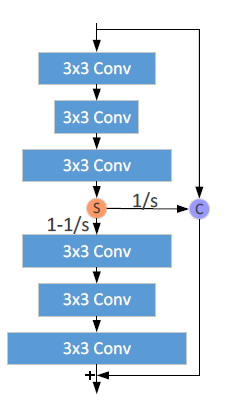
-Compression unit: 1x1conv
-First train the network with MAE loss and then fine-tune it by MSE loss
[CARN - ECCV2018] Fast, Accurate, and Lightweight Super-Resolution with Cascading Residual Network
其实就是把DRRN里resnet的连线改为densenet的连线,加了些1x1conv
-Global cascade:
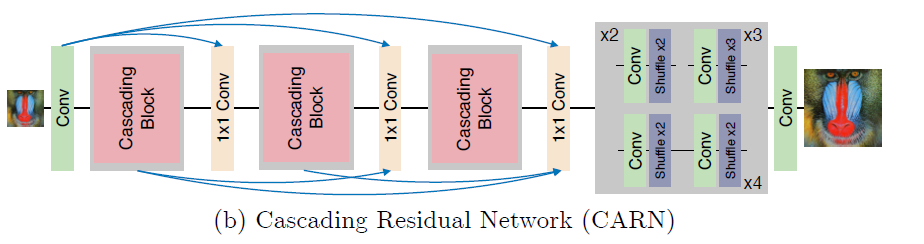
-Cascading block, local cascade and efficient residual (residual-E) block. And to further reduce the parameters, make the parameters of the Cascading blocks shared, effectively making the blocks recursive.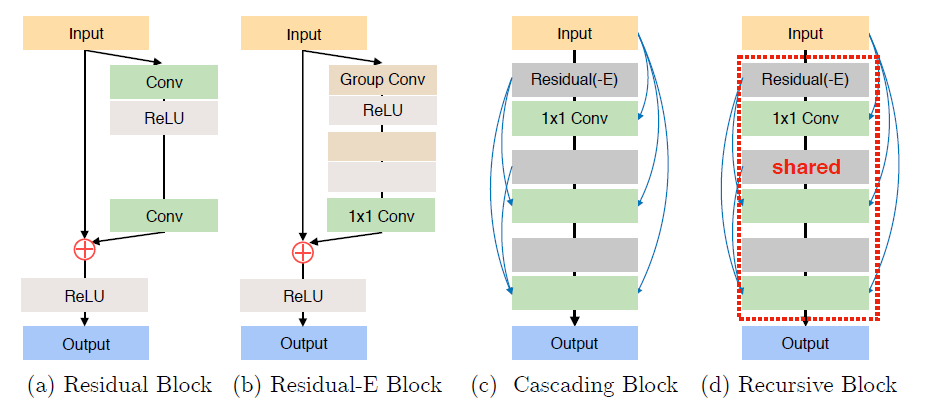
-Cascading on both the local and global levels has two advantages: 1) The model
incorporates features from multiple layers, which allows learning multi-level rep-
resentations. 2) Multi-level cascading connection behaves as multi-level shortcut
connections that quickly propagate information from lower to higher layers (and
vice-versa, in case of back-propagation).
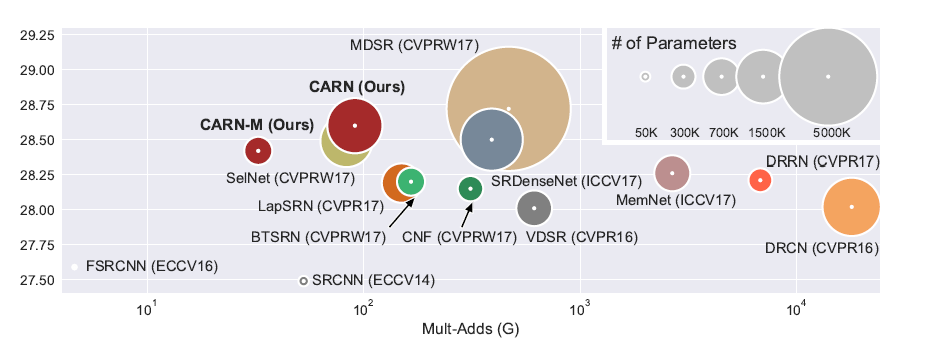
[RCAN - ECCV2018] Image Super-Resolution Using Very Deep Residual Channel Attention Networks
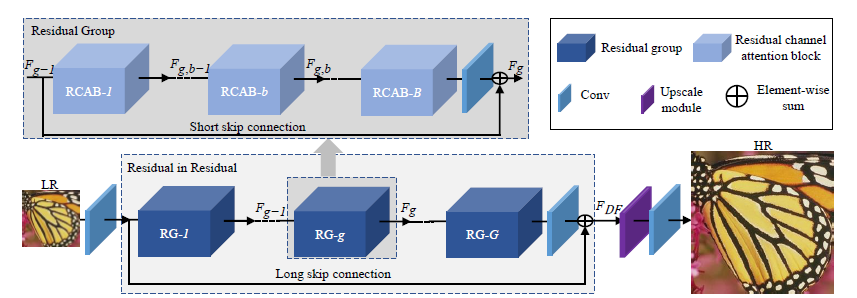
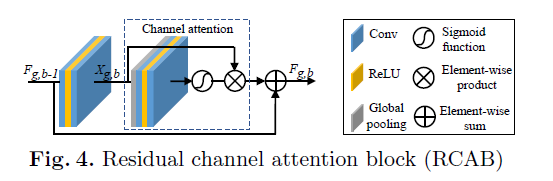
[SRRAM - arXiv1811] RAM: Residual Attention Module for Single Image Super-Resolution
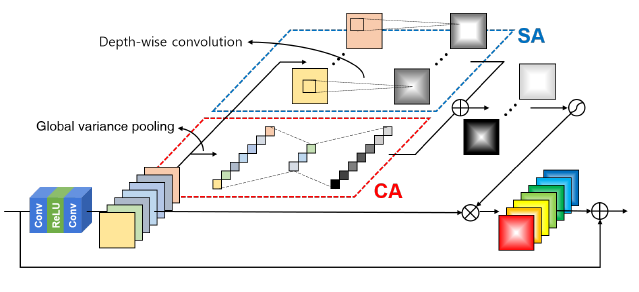

-Channel Attention: since SR ultimately aims at restoring high-frequency components of images,
it is more reasonable for attention maps to be determined using high-frequency statistics about the channels. To this end, we choose to use the variance rather than the average for the pooling method
-Spatial Attention: use depth-wise convolution
GAN based Approach
[SRGAN - CVPR2017] Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
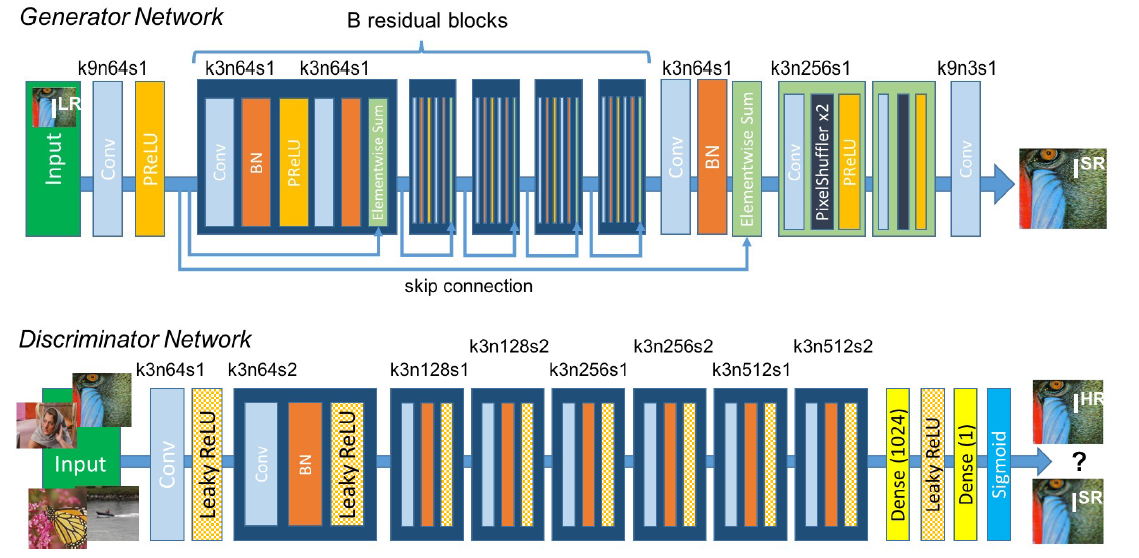
-Perceptual loss function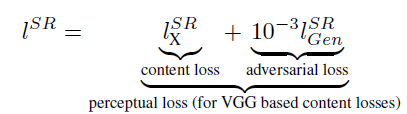
-content loss
With φij we indicate the feature map obtained by the j-th convolution (after activation) before the i-th maxpooling layer within the VGG19 network.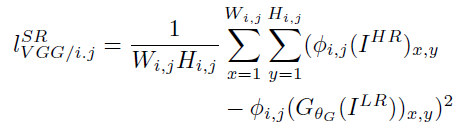
-adverarial loss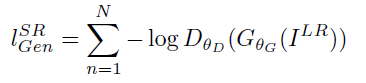
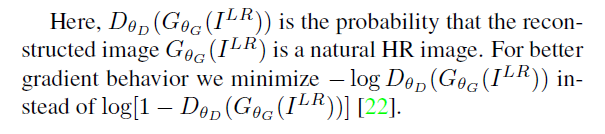
[EhanceNet - ICCV2017] EnhanceNet: Single Image Super-Resolution Through Automated Texture Synthesis
[SRFeat - ECCV2018] SRFeat: Single Image Super-Resolution with Feature Discrimination
-While GAN-based SISR methods show dramatic improvements over previous approaches in terms of perceptual quality, they often tend to produce less meaningful high-frequency noise in super-resolved images. We argue that this is because the most dominant difference between super-resolved images and real HR images is high-frequency information, where super-resolved images obtained by minimizing pixel-wise errors lack high-frequency details. The simplest way for a discriminator to distinguish super-resolved images from real HR images could be simply inspecting the presence of high-frequency components in a given im- age, and the simplest way for a generator to fool the discriminator would be to put arbitrary high-frequency noise into result images.
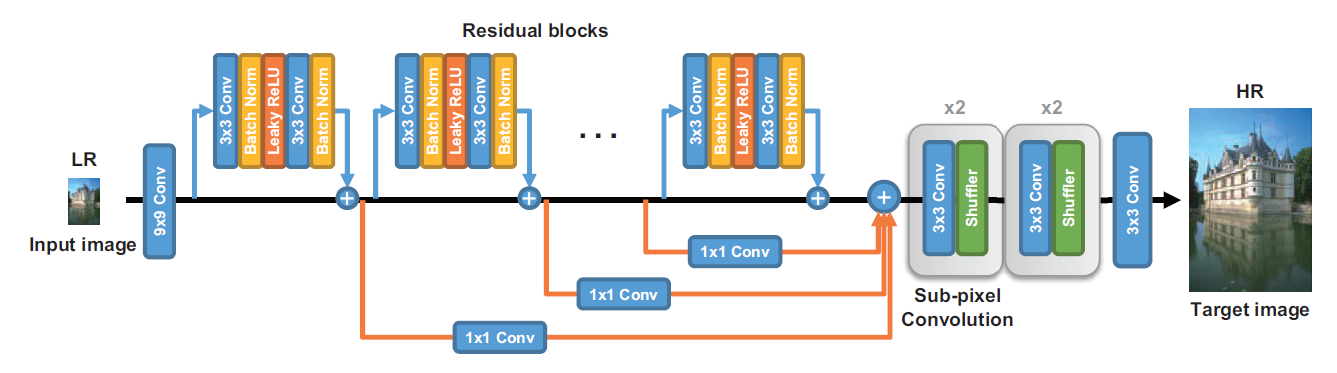
-First pre-train using MSE loss, then go adversarial training.
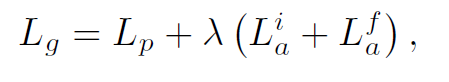
-Lp: perceptual Similarity Loss.
Lia : image gan loss.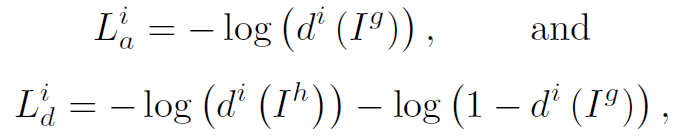
Lfa : feature gan loss.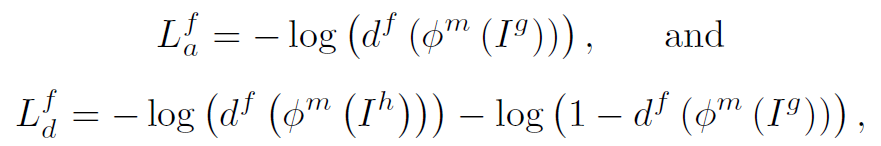
[ESRGAN - ECCV2018W] Enhanced Super-Resolution Generative Adversarial Networks

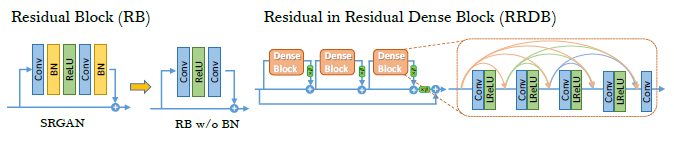
-Net Architecture:
Like EDSR: When the statistics of training and testing datasets differ a lot, BN layers tend to introduce unpleasant artifacts and limit the generalization ability. We empirically observe that BN layers are more likely to bring artifacts when the network is deeper and trained under a GAN framework.
Residual leaning.
Smaller initialization
-Relativistic Discriminator
A relativistic discriminator tries to predict the probability that a real image xr is relatively more realistic than a fake one xf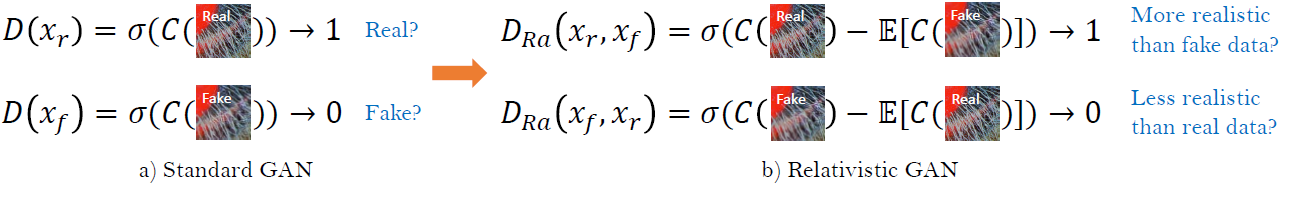
where E[ ] represents the operation of taking average for all fake or real data in the mini-batch.
The discriminator loss is then defined as: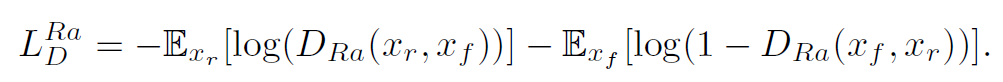
The adversarial loss for generator is in a symmetrical form: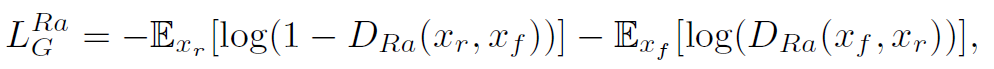
It is observed that the adversarial loss for generator contains both xr and xf . Therefore, our generator benefits from the gradients from both generated data and real data in adversarial training, while in SRGAN only generated part takes effect. The experiment shows this modification of discriminator helps to learn sharper edges and more detailed textures.
-Perceptual Loss:
Develop a more effective perceptual loss by constraining on features before activation rather than after activation. Two reasons: first, the activated features are very sparse; second, using features after activation also causes inconsistent reconstructed brightness
-total loss for the generator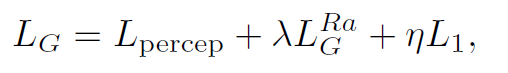
-Network Interpolation
To remove unpleasant noise in GAN-based methods while maintain a good perceptual quality
[RankSRGAN - ICCV2019] RankSRGAN: Generative Adversarial Networks with Ranker for Image Super-Resolution
Video
Four steps: feature extraction, alignment, fusion, and reconstruction.
[VESPCN - CVPR2017] Real-Time Video Super-Resolution with Spatio-Temporal Networks and Motion Compensation
[SPMC - ICCV2017] Detail-revealing Deep Video Super-resolution
[FRVSR - CVPR2018] Frame-Recurrent Video Super-Resolution
[DUF - CVPR2018] Deep Video Super-Resolution Network Using Dynamic Upsampling FiltersWithout Explicit Motion Compensation
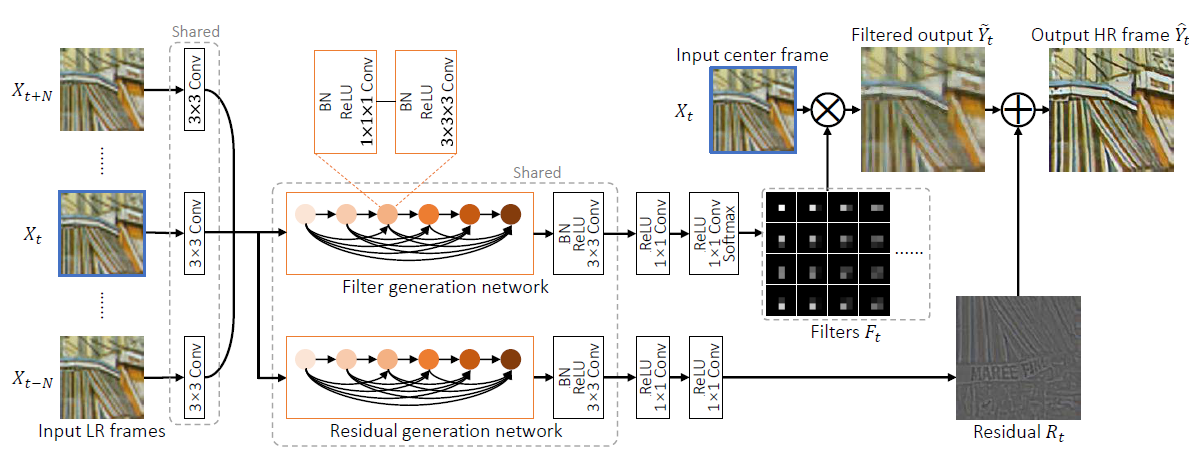
-Dynamic Upsampling Filters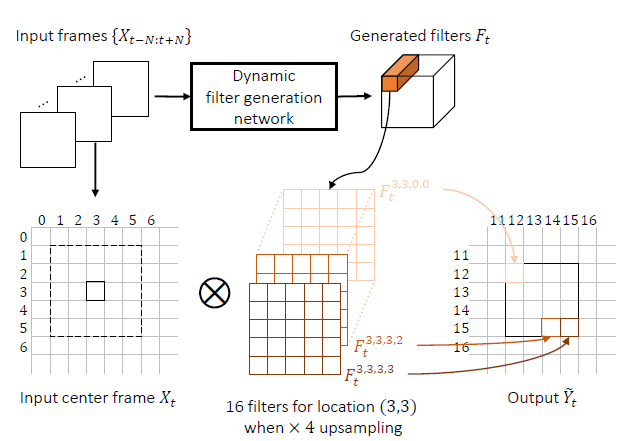
First, a set of input LR frames {Xt−N:t+N} (7 frames in our network: N = 3) is fed into the dynamic filter generation network. The trained network outputs a set of r2HW upsampling filters Ft of a certain size (5 × 5 in our network).(F的大小为: 5 x 5 x r2HW, 这里的r是scale factor)
然后对于原图中的一点,用周围5x5的点与F中5x5xr2依次相乘,得到rxr个点,从而upsampling了r倍。
-Residual Learning
The result after applying the dynamic upsampling filters alone lacks sharpness as it is still a weighted sum of input pixels.To address this, we additionally estimate a residual image to increase high frequency details
-Network Design
3D convolutional layers / filter and residual generation network are designed to share most of the weights
[EDVR - CVPRW2019] EDVR: Video Restoration with Enhanced Deformable Convolutional Networks