经验分享
Tricks
调参技巧
1.Adam: init_lr=5e-4(3e-4)(⭐⭐⭐⭐⭐),3e-4号称是Adam最好的初始学习率
2.lr schedule
- ReduceLROnPlateau,patience=4(5),gamma=0.1,这是我常用的一套组合,并不是最好的;
- StepLR,个人比较喜欢用这个,自己设定好在哪个epoch进行学习率的衰减,个人比较喜欢用的衰减步骤是[5e-4(3e-4), 1e-4, 1e-5, 1e-6],至于衰减位置,就需要自己有比较好的直觉,或者就是看log调参,对着2.1上训练的valid loss走势,valid loss不收敛了,咱就立刻进行衰减;
- CosineAnnealingLR+Multi cycle,这个相较于前两个,就不需要太多的调参,可以训练多个cycle,模型可以找到更多的局部最优,一般推荐min_lr=1e-6,至于每个cycle多少epoch这个就说不准了,不同数据不太一样。
3.finetune,微调也是有许多比较fancy的技巧,在这里不做优劣比较,针对分类任务说明。
- 微调方式一,最常用,只替换掉最后一层fc layer,改成本任务里训练集的类别数目,然后不做其余特殊处理,直接开始训练;
- 微调方式二,在微调一的基础上,freeze backbone的参数,只更新(预训练)新的fc layer的参数(更新的参数量少,训练更快)到收敛为止,之后再放开所有层的参数,再一起训练;
- 微调方式三,在微调方式二预训练fc layer之后或者直接就是微调方式一,可选择接上差分学习率(discriminative learning rates)即更新backbone参数和新fc layer的参数所使用的学习率是不一致的,一般可选择差异10倍,理由是backbone的参数是基于imagenet训练的,参数足够优秀同时泛化性也会更好,所以是希望得到微调即可,不需要太大的变化。
1 | optimizer = torch.optim.Adam([{'params': model.backbone.parameters(), 'lr': 3e-5}, {'params': model.fc.parameters(), 'lr': 3e-4}, ]) |
- 微调方式四,freeze浅层,训练深层(如可以不更新resnet前两个resnet block的参数,只更新其余的参数,一样是为了增强泛化,减少过拟合)。
4.Find the best init_lr,前面说到3e-4在Adam是较优的init_lr,那么如何寻找最好的init_lr?
- 出自fastai, lr_find(),其原理就是选取loss function仍在明显降低的较大的学习速率,优劣性其实也是相对而言,不一定都是最好的。
5.learing rate warmup,理论解释可以参 https://www.zhihu.com/question/338066667
6.如果模型太大的同时你的GPU显存又不够大,那么设置的batch size就会太小,如何在有限的资源里提升多一点?
- 梯度累计(gradient accumulation),其实就是积累多个batch的梯度之后,再进行梯度的回传做参数的更新,变相的增大了训练的batch size,但缺点是对Batch Normalization没影响的。。
- 如果你卡多,这时可以使用多卡并行训练,但要使用syncbn(跨卡同步bn),即增大了batch size,又对Batch Normalization起到相同的作用。
分类赛技巧
1.label smoothing
分类任务的标签是one-hot形式,交叉熵会不断地去拟合这个真实概率,在数据不够充足的情况下拟合one-hot容易形成过拟合,因为one-hot会鼓励正确类别与所属类别之间的差异性尽可能大,但其实有不少类别之间是极为相似的。label smoothing的做法其实就是将hard label变成soft label。
2.topk-loss(OHEM)
OHEM最初是在目标检测上提出来的,但其实思想是所有领域任务都通用的。意思就是提取当前batch里top k大的loss的均值作为当前batch的loss,进行梯度的计算和回传。其insight也很简单,就是一种hard mining的方法,一个batch里会有easy sample和hard sample,easy sample对网络的更新作用较小(loss值小,梯度也会小),而hard sample的作用会更大(loss值大,梯度值也会大),所以topk-loss就是提取hard sample。
1 | loss = criterion(logits, truth) |
3.weighted loss
weighted loss其实也算是一种hard mining的方法,只不过这种是人为地认为哪种类别样本更加hard,哪种类别样本更加easy。也就是说人为对不同类别的loss进行进行一个权重的设置,比如0,1类更难,设置权重为1.2,2类更容易,设置权重为0.8。。
1 | weights = [1.2, 1.2, 0.8] |
4.dual pooling
这种是在模型层进行改造的一种小trick了,常见的做法:global max/average pooling + fc layer,这里试concat(global max-pooling, global average pooling) + fc layer,其实就是为了丰富特征层,max pooling更加关注重要的局部特征,而average pooling试更加关注全局的特征。不一定有效,我试过不少次,有效的次数比较少,但不少人喜欢这样用。
1 | class res18(nn.Module): |
5.margin-based softmax
- 在人脸识别领域,基于margin的softmax loss其实就是对softmax loss的一系列魔改(large margin softmax、NormFace、AM-softmax、CosFace、ArcFace等等),增加类间 margin,当然也有其它的特点,如weight norm和基于余弦角度的优化等等。其共同目标都是为了获得一个更加具有区分度的feature,不易过拟合。
- 一个比较多同学忽略的点是,如果使用了margin-based softmax,往往连同开源repo里默认的超参数也一起使用了,比如s=32.0,m=0.5,但其实这两个参数的设定都是有一定的缘由,比如s值象征着超球体的体积,如果类别数较多,那么s应该设置大点。如果你没有很好的直觉,那grid search一波,搜索到适合的s和m值也不会花很多时间。
6.Lovasz loss
- 这个loss本来是出于分割任务上的,其优化的是IOU,但你如果仔细观察lovasz传入的logit和truth,可以发现是和multi label classification类似,logit和truth都是由多个1值的one-hot形式。所以在多标签分类任务上,其实是可以用lovasz loss来进行优化的,出自(Bestfitting)(https://www.kaggle.com/c/human-protein-atlas-image-classification/discussion/78109#latest-676029)
分类赛技巧(openset/检索)
1.BNNeck(出自罗浩博士的Bag of Tricks and A Strong Baseline for Deep Person Re-identification ),知乎链接一个更加强力的ReID Baseline, 其实就是在feature层和fc layer之间增加一层Batch Normalization layer,然后在retrieval的时候,使用BN后的feature再做一个l2 norm,也就是retrieval with Cosine distance。
1 | class res50(torch.nn.Module): |
2.margin-based softmax(上面已经说到)
3.triplet loss + softmax loss,结合metric learning,对feature进行多个loss的优化,triplet loss也是可以有很多的花样,Batch Hard Triplet Loss,是针对triplet loss的一种hard mining方法。
4.IBN,切换带有IBN block的backbone,搜图(open-set)往往test和train是不同场景下的数据,IBN block当初提出是为了提高针对不同场景下的模型泛化性能,提升跨域(cross domain)能力,在reid下的实验,IBN表现优异。
5.center loss
6.Gem,generalized mean pooling,出自Fine-tuning CNN Image Retrieval with No Human Annotation,提出的是一种可学习的pooling layer,可提高检索性能,代码出自 https://github.com/tuananh1007/CNN-Image-Retrieval-in-PyTorch/blob/master/cirtorch/layers/pooling.py
1 | class GeM(nn.Module): |
7.global feature + local features 将全局特征和多个局部特征一起融合,其实就是一种暴力融合特征的方法,对提升精度有一定的帮助,就是耗时相对只使用global feature来说很多点,此种方法可参考在reid常用的PCB(Beyond Part Models: Person Retrieval with Refined Part Pooling)或MGN(Learning Discriminative Features with Multiple Granularities for Person Re-Identification)方法
8.re-ranking,是一种在首次获取检索图的候选图里做一次重新排序,获得更加精准的检索,相对比较耗时间,不适合现实场景,适合比赛刷精度。
分割赛技巧
1.Unet Unet可以说是在kaggle的语义分割赛里的一个较优的选择,许多top solution都是使用了Unet,FPN也是一个非常不错的选择。
2.Unet的魔改
现在有个开源库其实是已经集成了许多不同分割网络,表现也是相对不错的,如果觉得自己修改比较困难,或者自己改得不够好,可以尝试使用这个库segmentation_models_pytorch
- 很多top solution都是修改Unet的Decoder,最常见的就是增加scse block和Hypercolumn block,也有一些是使用了CBAM(Convolutional Block Attention Module,bestfitting比较喜欢用)或BAM(Bottleneck attention module),这些注意力block一般是放在decoder不同stage出来的feature后面,因为注意力机制往往都是来优化feature的。
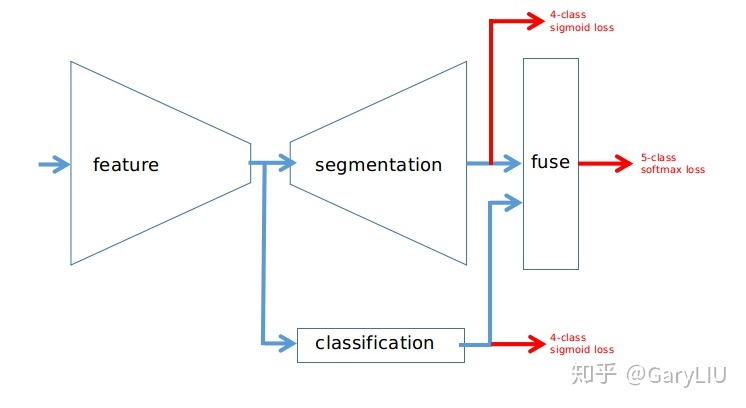
- dual head(multi task learning),也就是构造一个end2end带有分割与分类的模型。同时,多任务学习往往会降低模型过拟合的程度,并可以提升模型的性能。
1 | import segmentation_models_pytorch as smp |
3.lovasz loss 之前在TGS Salt Identification的适合,lovasz对分割的效果的表现真的是出类拔萃,相比bce或者dice等loss可以提高一个档次。但是最近的分割赛这个loss的表现就一般,猜测是优化不同metric,然后不同loss就会带来不同的效果,又或者是数据的问题。
4.dice loss for postive,bce loss for negtive 主要就是将分割任务划分两个任务:1. 分割任务,2. 分类任务 dice loss可以很好的优化模型的dice score,而bce loss训练出来的分类器可以很好地找出negtive sample,两者结合可以达到一种非常好效果,详细解说可以参考我之前的一个solution: Kaggle Understanding Clouds 7th place总结
通用技巧
1.TTA(Test Time Augmentation) 一种暴力测试的方法,将有效的增强方式得到多个不同的input,然后进行infer,得到多个结果进行融合,一般会比原始input会高不少。这种方法的缘由就是希望通过对input进行不同的变换方式获取多个不同的但重要的特征,然后可以得到多个具有差异性的预测结果。
2.多尺度训练,融合 在训练期间,随机输入多种尺度的图像进行训练,如(128128,196196,224224,256256,384*384等等)然后测试的时候可适当的选取其中某几个尺度表现优异的预测结果出来融合,这种方法其实就是为了提升模型对尺度的变换的鲁棒性,不易受尺度变换的影响。
3.Ensemble
- Snapshot Ensembles,这个方法常在与cycle learning rate的情况下使用,在不同cycle下,模型会产出多个不同的snapshot weight(多个不同的局部最优,具有差异性),这时可以将这几个snapshot model一起进行推断,然后将预测结果进行平均融合。
- SWA, Stochastic Weight Averaging,随机权重平均,其实现原理当模型在训练时收敛到一定程度后,开始追踪每次epoch后得到的模型的平均值,有一个计算公式和当前的模型权重做一个平均得到一个最终的权重,提高泛化性能。
- stacking,在分类任务里,stacking是作为一种2nd level的ensemble方法,将多个“准而不同”的基分类器的预测集成与一身,再扔进去一个简单的分类器(mlp、logit regression、simple cnn,xgboost等)让其自己学习怎么将多个模型融合的收益做到最高。一般数据没有问题的话,stacking会更加稳定,不易过拟合,融合的收益也会更高。
4.设计metric loss 许多小伙伴会有这样一个疑惑,比赛的评测metric往往和自己训练时所使用的loss优化方向不是那么一致。比如多标签分类里的metric是fbeta_score,但训练时是用了bce loss,经常可以看到val loss再收敛后会有一个反弹增大的过程,但此时val fbeta_score是还在继续提升的。这时就可以针对metric来自行设计loss,比如fbeta loss就有。
5.semi-supervised learning
- recurssive pseudo-label(伪标签),伪标签现在已经是kaggle赛里一个必备工具了,但是这是个非常危险的操作,如果没有筛选好的伪标签出来,容易造成模型过拟合伪标签里的许多噪声。比较安全的方法是:1. 筛选预测置信度高的样本作为伪标签,如分类里,再test里的预测概率是大于0.9的,则视为正确的预测,此时将其作为伪标签来使用。2. 帮第一次的伪标签扔进去训练集一起训练后,得到新的模型,按相同的规则再次挑一次伪标签出来。3. 如此不断循环多次,置信度的阈值可以适当作调整。
- mean teacher,在这里给涛哥在Recursion Cellular Image Classification第三名的方案做个广告,end2end semi-supervised learining pipeline。
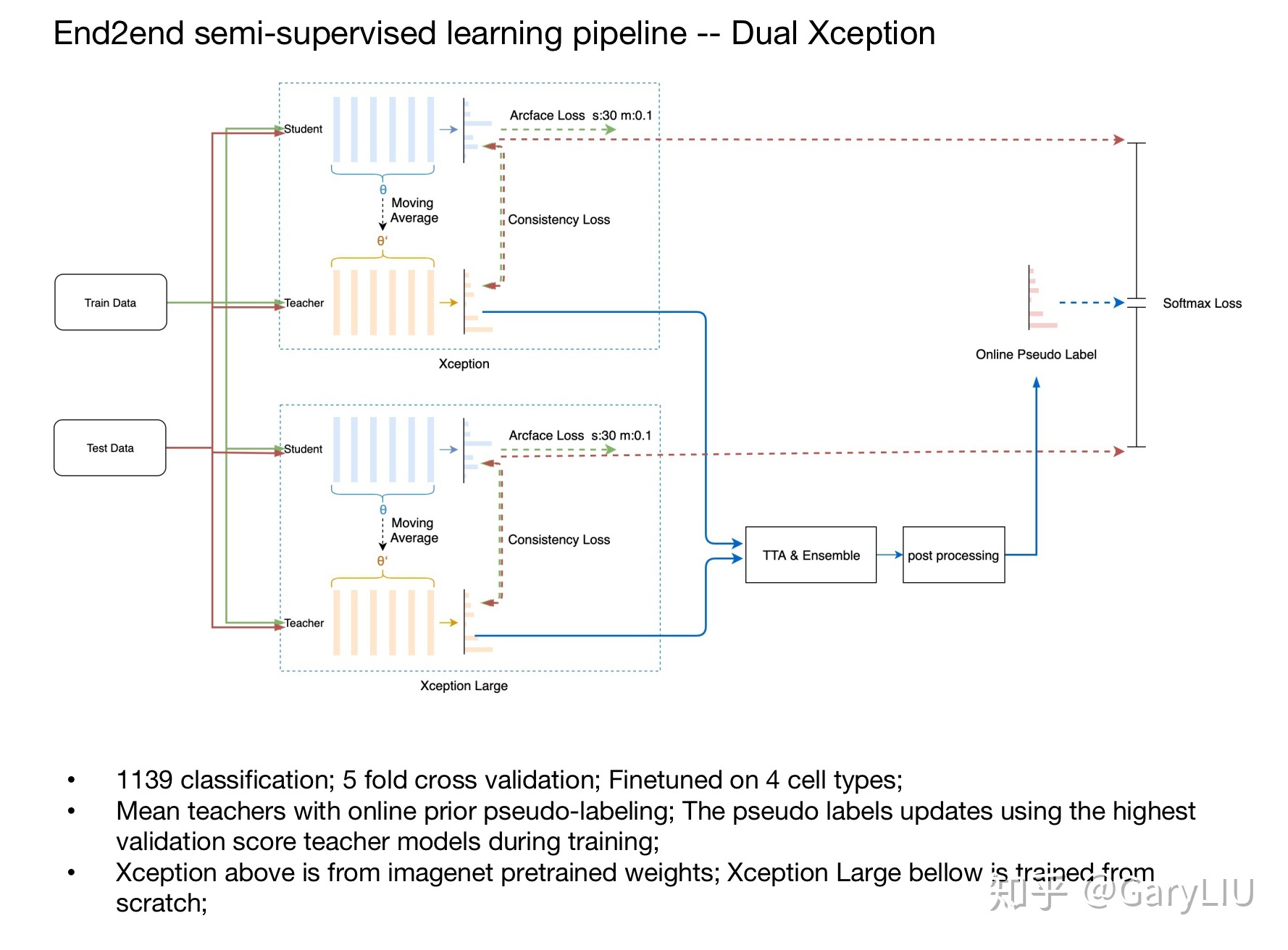
- knowledge distillation(知识蒸馏),此方法有助于提高小模型(student)的性能,将大模型(teacher)的预测作为soft label(用于学习teacher的模型信息)与truth(hard label)扔进去给小模型一起学习,当然两个不同label的loss权重需要调一调。当然,蒸馏的方法有很多种,这只是其中一种最简单的方法。蒸馏不一定用于训练小模型,大模型之间也是可以一同使用的
数据增强与预处理
1.h/v flip(水平垂直翻转),95%的情况下都是有效的,因为不怎么破坏图像空间信息。
2.random crop/center crop and resize,在原图进行crop之后再resize到指定的尺度。模型的感受野有限,有时会看不到图像中一些分布比较边缘或者是面积比较小的目标物体,crop过后其占比有更大,模型看到的机会也会更多。适用性也是比较大的。
3.random cutout/erasing(随机擦除),其实就是为了随机擦除图像中局部特征,模型根据有限的特征也可以判断出其属性,可提高模型的泛化性。
4.AutoAugment,自己设定一些规则policy,让模型自己寻找合适的数据增强方式,需要消耗比较多的计算资源。
5.mixup 一种与数据无关的数据增强方式,即特征之间的线性插值应导致相关标签之间的线性插值,扩大训练分布。意思是两个不同的label的样本进行不同比例的线性插值融合,那么其label也应该是相同比例关系进行线性融合。(上图)
6.Class balance 主要就是针对数据不平衡的情况下进行的操作,一般是针对采样方法,或者在loss上做处理,如focal loss、weighted loss等。
7.图像预处理,许多看似有效的预处理操作,但是并不一定有效,如在医学领域的图像,许多肉眼观察良好的预处理的方式,实际上是破坏了原图真实类别关联的特征,这种方面需要相关领域知识。
如何选择更好的backbone模型
1.对于baseline,从resnet18/34 or efficientnet-B0起步,把所有work的技巧(loss/augmentation/metric/lr_schedule)调好之后,这时就应该大模型(deeper);
2.当更好需要换模型的时候,是不是就需要自己去设计/构造新模型呢?其实在比赛的短期里,重新设计一个新的backbone出来是不提倡的,因为模型不仅要work,还要重新在imagenet上预训练,时间消耗巨大,不合适比赛;
3.由于学术界里,sota模型多之又多,那如何选择?从个人经验总结来看,比较推荐se-resnext50/101、SENet154(太大,很少用),带有se block的resnet,都不同类型的任务都有一定的通用性,性价比也较高;efficientnet系列(最近在某些比赛里还优于se-resnext)可以上到B3,B5,有条件的B7都没问题。其他的sota模型,可以尝试Xception,inception-resnetV2等等。