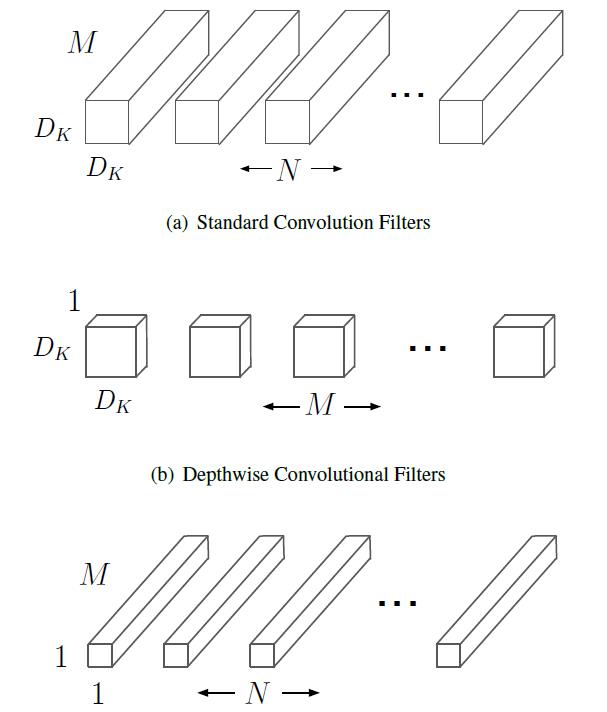
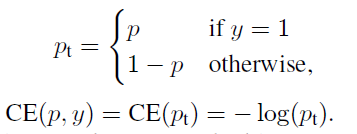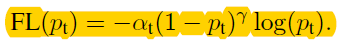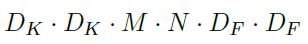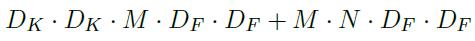常用命令
| vncserver -geometry 1920x1080 | 创建一个1920x1080的vnc |
| vncserver -kill :1 | 删除ID为1的vnc |
| mkdir XXX | 建文件夹 |
| mkdir -p AAA/BBB | 建BBB,若AAA不存在则先建AAA |
| cd XX | 到某个目录 |
| cd .. | 返回上一级目录 |
| cd ~ | 到home目录 |
| pip intsall | 装某一个python的库 |
| nvidia-smi | 查看gpu使用情况 |
| ./XX.sh | 运行某个.sh文件 |
| rm -rf XXX | 删除整个文件夹 |
| rm XXX | 删除一个文件 |
| cp -a XX(source) YY(destination) | 将整个XX复制到YY |
| mv XX YY | 将XX移动到YY |
| df -h | 查看系统中文件的使用情况 |
| du -sh * | 查看当前目录下各个文件及目录占用空间大小 |
| du -sh FILE/ | 查看目录文件总大小 |
| tar | |
安装
zjuvpn安装
https://www.cc98.org/topic/2323871
1.删除原来的xl2tpd包:
1 | sudo dpkg --purge xl2tpd |
2.下载:
https://pan.baidu.com/s/1eRNQwng#list/path=%2F
3.安装:
1 | sudo dpkg -i xl2tpd_1.1.12-zju2_i386.deb |
报错:没有iproute 所以要先装一个:1
sudo apt-get install iproute
4.配置:
1 | sudo vpn-connect -c |
按照提示操作, 注意用户名 学号后面要加@a
5.连接:1
sudo vpn-connect
6.断开:
1 | sudo vpn-connect -d |